Resultados de la 4° Edición de la Encuesta KIWI de Sueldos de RH realizada por R4HR, el Club de R para RRHH
sueldos
kiwi
Author
R4HR
Published
November 30, 2023
Ver código
# Liberías -----library(tidyverse)library(funModeling)library(gt)library(scales)library(extrafont)library(ggalt)library(kableExtra)library(wordcloud)library(networkD3)library(ggpmisc)library(data.table)library(ggeconodist)library(wordcloud2) library(tidytext)library(igraph)library(ggraph)library(grid)# Configuraciones generales ----options(scipen =999) # Modifica la visualización de los ejes numérico a valores nominalesloadfonts(quiet =TRUE) # Permite cargar en R otros tipos de fuentes.# Estilo limpio sin líneas de fondoestilo <-theme(panel.grid =element_blank(),plot.background =element_rect(fill ="#FBFCFC"),panel.background =element_blank(),plot.title.position ="plot")# Estilo limpio con líneas de referencia verticales en gris claroestilov <-theme(panel.grid =element_blank(),plot.background =element_rect(fill ="#FBFCFC"),panel.background =element_blank(),panel.grid.major.x =element_line(color ="#AEB6BF"),plot.title.position ="plot")# Estilo limpio con líneas de referencia horizontales en gris claroestiloh <-theme(panel.grid =element_blank(),plot.background =element_rect(fill ="#FBFCFC"),panel.background =element_blank(),panel.grid.major.y =element_line(color ="#AEB6BF"),plot.title.position ="plot")genero <-c("#8624F5", "#1FC3AA", "#FFD129", "#75838F") #Violeta - Verde - Amarillo - Grisgenero3 <-c("#8624F5","#FFD129", "#1FC3AA")colores <-c("#8624F5", "#1FC3AA")azul <-"#344D7E"verde <-"#1FC3AA"rosa1 <-"#B95192"rosa2 <-"#EE5777"naranja <-"#FF764C"amarillo <-"#FFD129"gris <-"#75838F"lila <-"#8624F5"rojo <-"#943126"col4 <-c(azul, lila, rosa1, rosa2)col5 <-c(azul, lila, rosa1, rosa2, naranja)col6 <-c(azul, lila, rosa1, rosa2, naranja, amarillo)# Creo un objeto con un texto que se va a repetir mucho a lo largo del análisisfuente <-"Fuente: Encuesta KIWI de Sueldos de RRHH 2023"# Creo objetos para formatear las etiquetas numéricas de los ejes x e yeje_x_n <-scale_x_continuous(labels =comma_format(big.mark =".", decimal.mark =","))eje_y_n <-scale_y_continuous(labels =comma_format(big.mark =".", decimal.mark =","))eje_x_p <-scale_x_continuous(labels =percent_format(accuracy =1))eje_y_p <-scale_y_continuous(labels =percent_format(accuracy =1))############################# Cargar datos -----rh23 <-read_delim("https://raw.githubusercontent.com/r4hr/kiwi2023/main/data/rh_2023.csv",delim =";") %>% janitor::clean_names()# Freelancersfreelo23 <-read_delim("https://raw.githubusercontent.com/r4hr/kiwi2023/main/data/freelancers_2023.csv", delim =";") %>% janitor::clean_names()# Base Originalkiwi <-read_delim("https://raw.githubusercontent.com/r4hr/kiwi2023/main/data/kiwi_2023.csv", delim =";") %>% janitor::clean_names()##### ## Bases anteriores de relación de dependencia# 2020kiwi20 <-read_delim("https://raw.githubusercontent.com/r4hr/kiwi2022/main/data/rh_2020.csv", delim =";") %>% janitor::clean_names() %>%mutate(anio =2020)# 2021kiwi21 <-read_delim("https://raw.githubusercontent.com/r4hr/kiwi2022/main/data/rh_2021.csv",delim =";") %>% janitor::clean_names() %>%mutate(anio =2021)# 2022kiwi22 <-read_delim("https://raw.githubusercontent.com/r4hr/kiwi2022/main/data/rh_2022.csv",delim =";") %>% janitor::clean_names() %>%mutate(anio =2022)
Ver código
# Agrupar puestosrh23 <- rh23 %>%mutate(puesto =fct_collapse(puesto, "Administrativo"=c("Administrativo", "Generalista"),"Responsable"=c("Responsable","Coordinador","Coordinador para 3 países","Coordinadora", "Supervisor"),"Gerente"=c("Gerente", "Team Leader")),puesto =factor(puesto, levels =c("Director", "Gerente","Jefe", "Responsable","HRBP", "Analista","Administrativo","Pasante")))# Agrupar funcionesrh23 <- rh23 %>%mutate(funcion =fct_collapse(funcion,"Generalista"=c("Generalista","Auxiliar (tareas hard y soft)","Coordinadora","Dirección Gral del área","Gestión de personas en general","HRBP","Todas","Todo Generalista","Todo lo anterior","coordino el equipo en general","generalista","todo","varias de la lista: reclutamiento y seleccion, adm de personal, compensaciones y beneficios, capacitacion y desarrollo, comunicacion interna, diseño organizacional, tareas generalistas"),"Payroll / Liquidación de sueldos"=c("Payroll / Liquidación de sueldos", "Payroll, Talent acquisition, Talent Management,","Analisis Libranzas"),"Administración de personal"=c("Administración de personal","Control Documentario"),"Reclutamiento y selección"=c("Reclutamiento y selección","Analista Soft (Empleos, Comunicaciones Internas, Capacitación y Desarrollo)","Empleos y RRLL"),"RSE"=c("RSE", "Recursos humanos y relaciones con la comunidad"),"Diseño organizacional"=c("Diseño organizacional","Cultura","Transformación de RH"),"Relaciones laborales"=c("Relaciones laborales","Ser el nexo con empleados, entablar relaciones, acompañarlos en lo que necesiten")))# Limpieza tipo contrataciónrh23 <- rh23 %>%mutate(tipo_contratacion =fct_collapse(tipo_contratacion,"Indeterminado"=c("Indeterminado","Relac depend ncoa")))
Introducción
R4HR Club de R para RRHH es una comunidad de aprendizaje de programación de R para profesionales y estudiantes que trabajen o quieran trabajar en RRHH.
Somos una comunidad que usa mayormente datos de ejemplo relacionados con RRHH, y que genera contenido en castellano para eliminar las barreras en el aprendizaje y facilitar que más personas adopten las herramientas de análisis de datos en sus trabajos.
También podés ver todo el contenido que generamos en los siguientes links:
Pueden acceder a los datos crudos desde este link.
Ver código
# Respuestas en relación de dependenciapais_rd <- rh23 %>%group_by(pais) %>%tally() %>%ungroup()# Respuestas de freelancerspais_freelo <- freelo23 %>%group_by(pais) %>%tally() %>% ungroup# Uno los dataframes paises_kiwi <-full_join(pais_freelo, pais_rd, by ="pais") %>%mutate(n.x =coalesce(n.x, 0),n.y =coalesce(n.y, 0),n = n.x + n.y)
Motivaciones
Una de las barreras a la hora de aprender People Analytics es que en RRHH trabajamos con datos sensibles, por eso es muy difícil acceder a sets de datos para practicar. Por eso, e inspirados en la Encuesta de SysArmy, una comunidad de tecnología, que entre otras cosas, organiza eventos como Nerdearla, hicimos nuestra propia encuesta, relevando datos de profesionales que trabajan tanto bajo relación de dependencia como de manera freelance. El relevamiento de datos lo hicimos entre el 1 y el 31 de octubre de 2023.
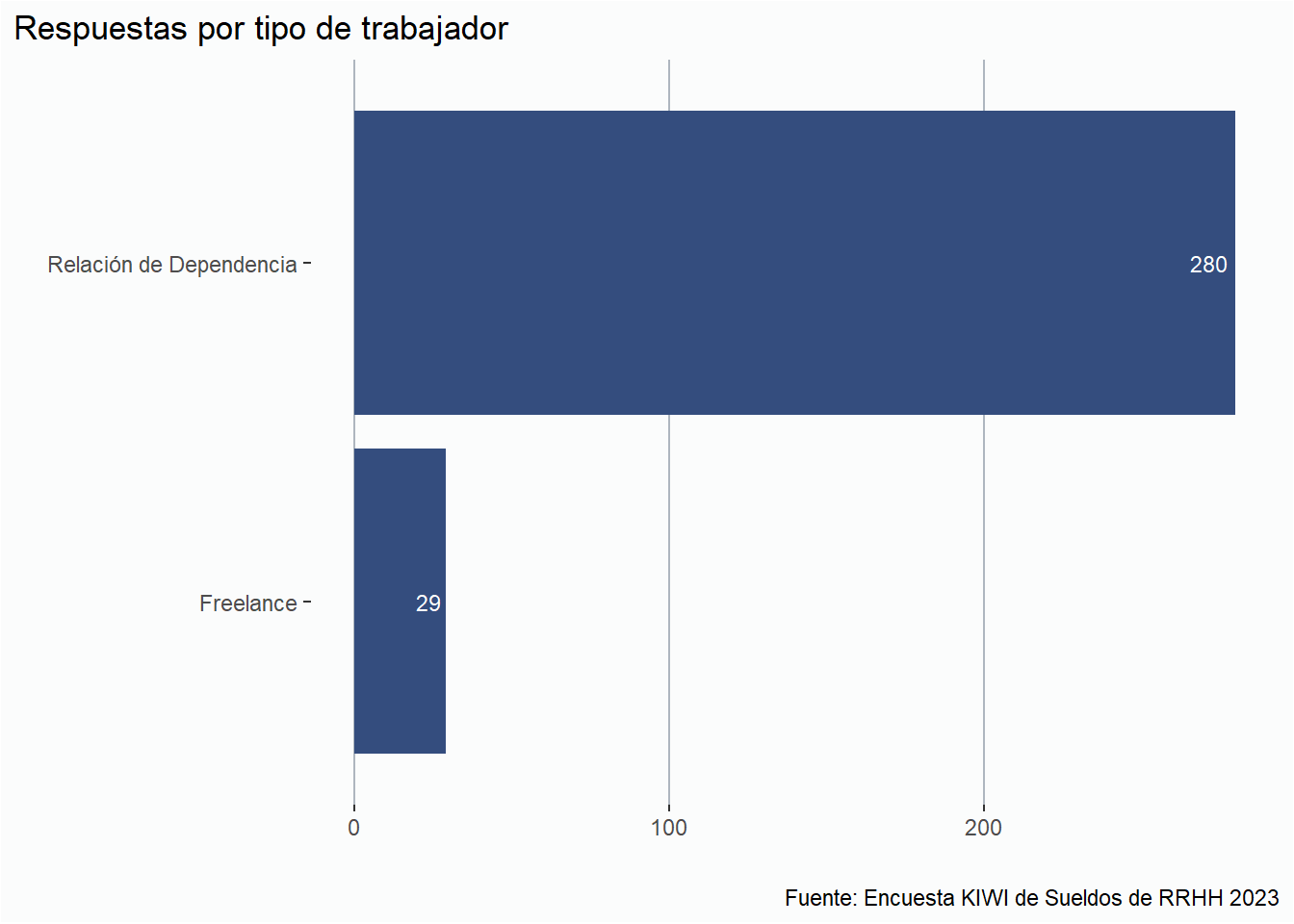
En esta edición recibimos 309 respuestas de 10 países diferentes.
Del total de respuestas recibidas, 280 son de personas que trabajan en relación de dependencia en RRHH, mientras que 29 personas trabajan de manera freelance.
Ver código
paises_kiwi <- paises_kiwi %>%group_by(pais) %>%summarise(total_freelo =sum(n.x),total_rd =sum(n.y)) %>%ungroup() %>%pivot_longer(cols =c("total_freelo", "total_rd"),names_to ="trabajo",values_to ="rtas")kiwi %>%select(trabajo) %>%group_by(trabajo) %>%count() %>%ggplot(aes(x = n, y = trabajo)) +geom_col(fill = azul) + estilov +geom_text(aes(label = n), # Indica la cantidad de decimalessize =3, # Cambia el tamaño de la letrahjust =1.2, # Mueve la etiqueta para la izquierdacolor ="white",family ="Roboto") +labs(title ="Respuestas por tipo de trabajador", x ="", y ="", caption = fuente)
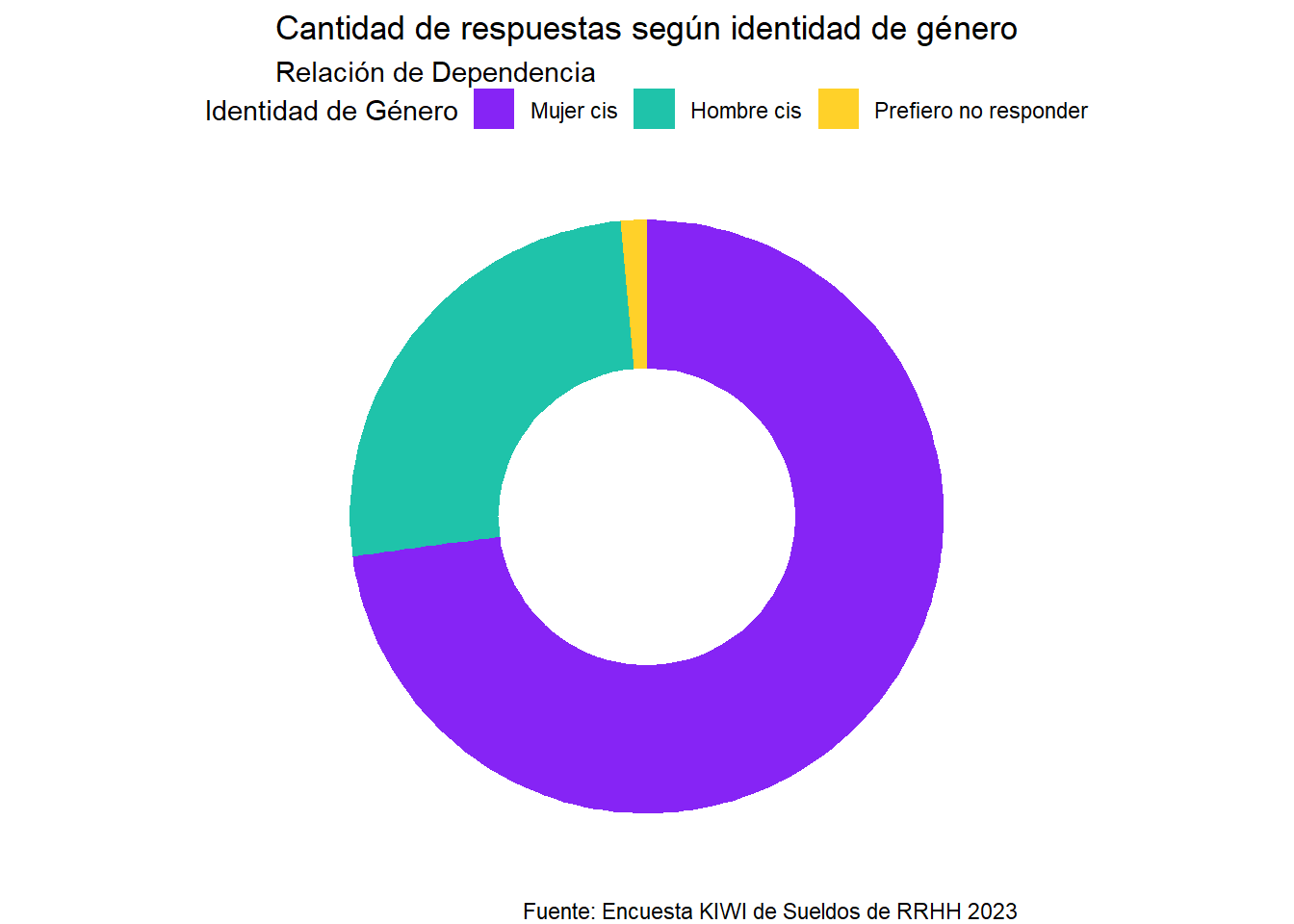
Como aclaración, cuando nos referimos a la identidad de género de las personas, utilizamos los términos Mujer cis/Mujer trans y Hombre cis/Hombre trans para poder reflejar con mayor precisión el abánico de identidades y percepciones.
El térmiino “cis” hace referencia a que la persona se identifica con el mismo género con el que nació.
Dicho esto, las respuestas según la identidad de género de las personas que participaron es la siguiente:
Ver código
# Gráfico para relación de dependencia----rh23 <- rh23 %>%mutate(genero =fct_collapse(genero, "Hombre cis"=c("Hombre cis", "Hoimbre", "Hombre"),"Mujer cis"=c("Mujer cis", "Mujer")))div <- rh23 %>%select(genero) %>%mutate(genero =factor(genero, levels =c("Mujer cis", "Hombre cis", "Prefiero no responder"))) %>%group_by(genero) %>%summarise (n =n()) %>%mutate(freq = n/sum(n)) %>%arrange(-n)# Compute the cumulative percentages (top of each rectangle)div$ymax <-cumsum(div$freq)# Compute the bottom of each rectanglediv$ymin <-c(0, head(div$ymax, n=-1))# Compute label positiondiv$labelPosition <- (div$ymax + div$ymin) /2# Compute a good labeldiv$label <-paste0(div$genero, "\n Cant: ", div$n)# Make the plotggplot(div, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=genero)) +geom_rect() +coord_polar(theta="y") +# Try to remove that to understand how the chart is built initiallyxlim(c(2, 4)) +# Try to remove that to see how to make a pie chartscale_fill_manual(values =c(lila, verde, amarillo)) +theme_void() +theme(legend.position ="top",panel.background =element_blank(),plot.title.position ="plot",text =element_text(family ="Roboto")) +labs(title ="Cantidad de respuestas según identidad de género",subtitle ="Relación de Dependencia",fill ="Identidad de Género", caption = fuente)# Gráfico de freelancers ----# freelo23 <- freelo23 %>% # mutate(genero = fct_collapse(genero, "Mujer cis" = c("Mujer cis", "Mujer")))div <- freelo23 %>%select(genero) %>%group_by(genero) %>%summarise (n =n()) %>%mutate(freq = n/sum(n)) %>%arrange(-n)# Compute the cumulative percentages (top of each rectangle)div$ymax <-cumsum(div$freq)# Compute the bottom of each rectanglediv$ymin <-c(0, head(div$ymax, n=-1))# Compute label positiondiv$labelPosition <- (div$ymax + div$ymin) /2# Compute a good labeldiv$label <-paste0(div$genero, "\n Cant: ", div$n)# Make the plotggplot(div, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=genero)) +geom_rect() +coord_polar(theta="y") +# Try to remove that to understand how the chart is built initiallyxlim(c(2, 4)) +# Try to remove that to see how to make a pie chartscale_fill_manual(values =c(verde, lila)) +theme_void() +theme(legend.position ="top",panel.background =element_blank(),plot.title.position ="plot",text =element_text(family ="Roboto")) +labs(title ="Cantidad de respuestas según identidad de género",subtitle ="Freelancers",fill ="Identidad de Género", caption = fuente)
En resumen, más de dos tercios de las personas que participaron de esta encuesta son mujeres cis. En esta edición no hemos recibidos respuestas de personas trans.
En esta sección nos dedicaremos a comparar los sueldos entre los países. En primer lugar, hay que resaltar que los resultados no son representativos de los mercados de los países, sino que lo son de los datos recolectados.
Por otra parte, la baja cantidad de respuestas recolectadas de otros países fuera de la Argentina, nos hace imposible, hacer un análisis comparado representativo de los puestos. Sin embargo, hay algunos datos interesantes para analizar.
Primero, analicemos los sueldos de los trabajadores en relación de dependencia, de cuyos países hayamos recibido al menos 3 respuestas.
Ver código
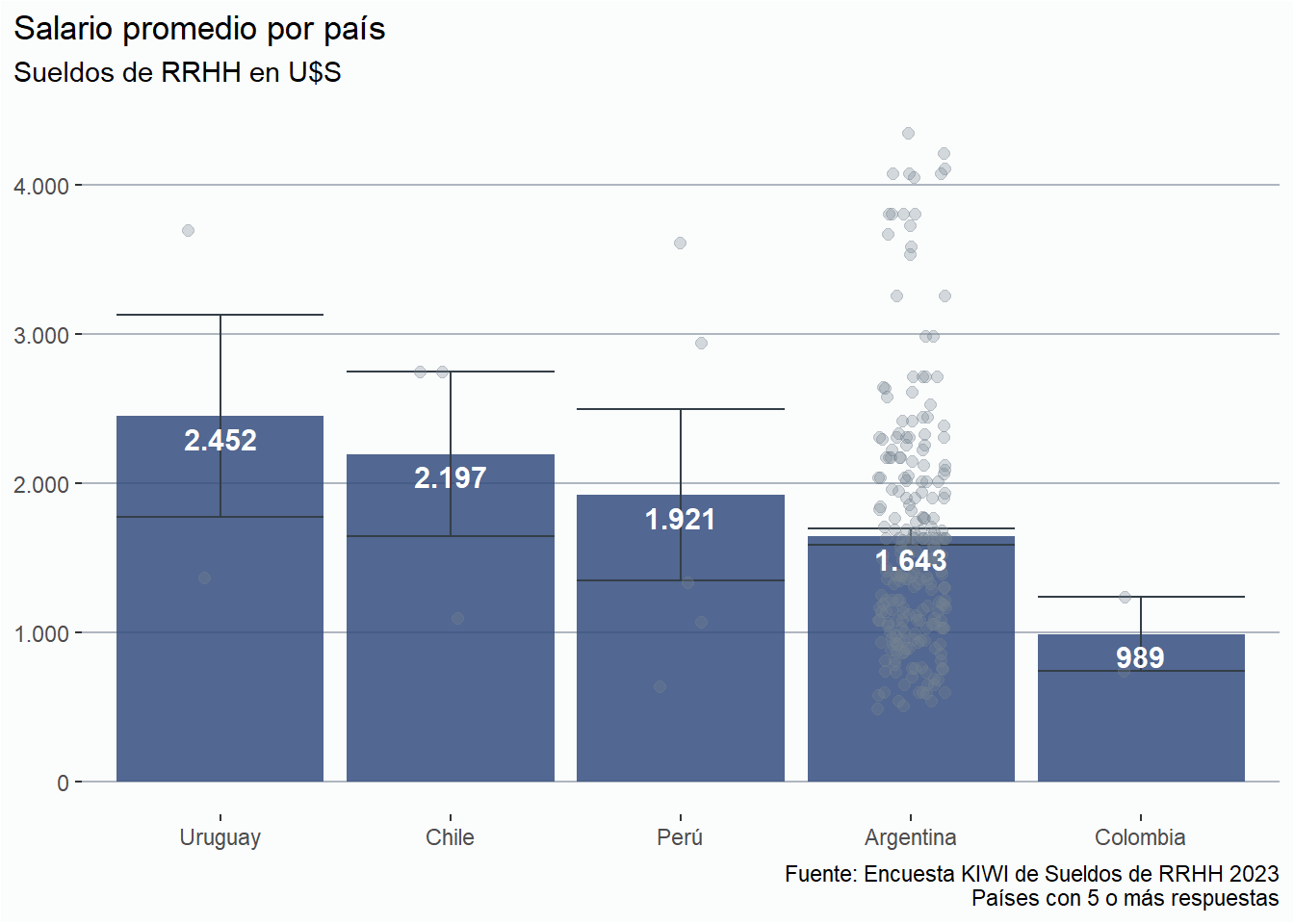
sueldos_dolar <- rh23 %>%select(puesto, sueldo_dolar, pais, tipo_contratacion)# Eliminamos los sueldos que están dentro del rango entre los percentiles 5 y 95numericos <-profiling_num(sueldos_dolar)poda_p05 <- numericos[1,6]poda_p95 <- numericos[1,10]# Dado que los percentiles 5 y 95 están en U$488 y 4355 respectivamente, # podamos todo lo que esté fuera de ese rangomedia_pais <- sueldos_dolar %>%filter(pais %in%c("Argentina", "Chile", "Perú", "Uruguay", "Colombia"),between(sueldo_dolar,poda_p05,poda_p95)) %>%group_by(pais) %>%summarise(sueldop =list(mean_se(sueldo_dolar))) %>%unnest(cols =c(sueldop)) sueldo_dolar_pais <- rh23 %>%select(pais, sueldo_dolar) %>%filter(between(sueldo_dolar, poda_p05, poda_p95), pais %in%c("Argentina", "Chile", "Perú", "Uruguay", "Colombia"))# Gráficoggplot(media_pais, aes(reorder(pais, -y), y = y))+geom_col(fill = azul, alpha =0.85) +geom_errorbar(aes(ymin = ymin,ymax = ymax), position ="dodge", color ="#333e47")+geom_point(data = sueldo_dolar_pais, aes(x = pais, y = sueldo_dolar), alpha =0.3, size =2, color ="#75838F",position =position_jitter(width =0.15))+geom_text(aes(label =comma(round(x=y, 0), big.mark =".", decimal.mark =","),vjust =1.5, fontface ="bold"), size =4, color ="white",family ="Roboto")+ eje_y_n +labs(title ="Salario promedio por país",subtitle ="Sueldos de RRHH en U$S",caption =paste0(fuente,"\nPaíses con 5 o más respuestas"),x =NULL, y =NULL) + estiloh
Similar con lo visto en ediciones pasadas, Uruguay y Chile tienen los salarios de RRHH más altos en la región.
Ver código
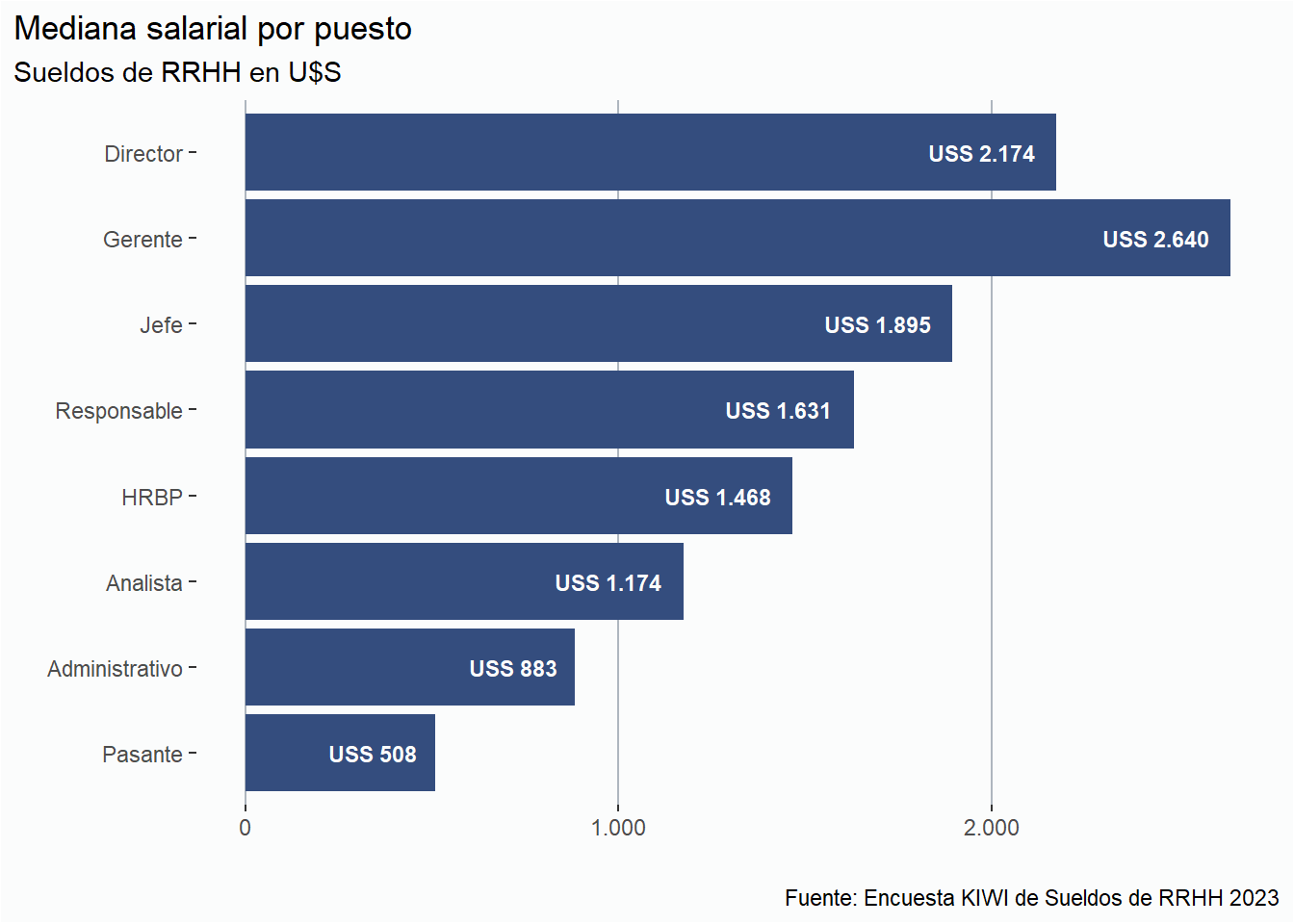
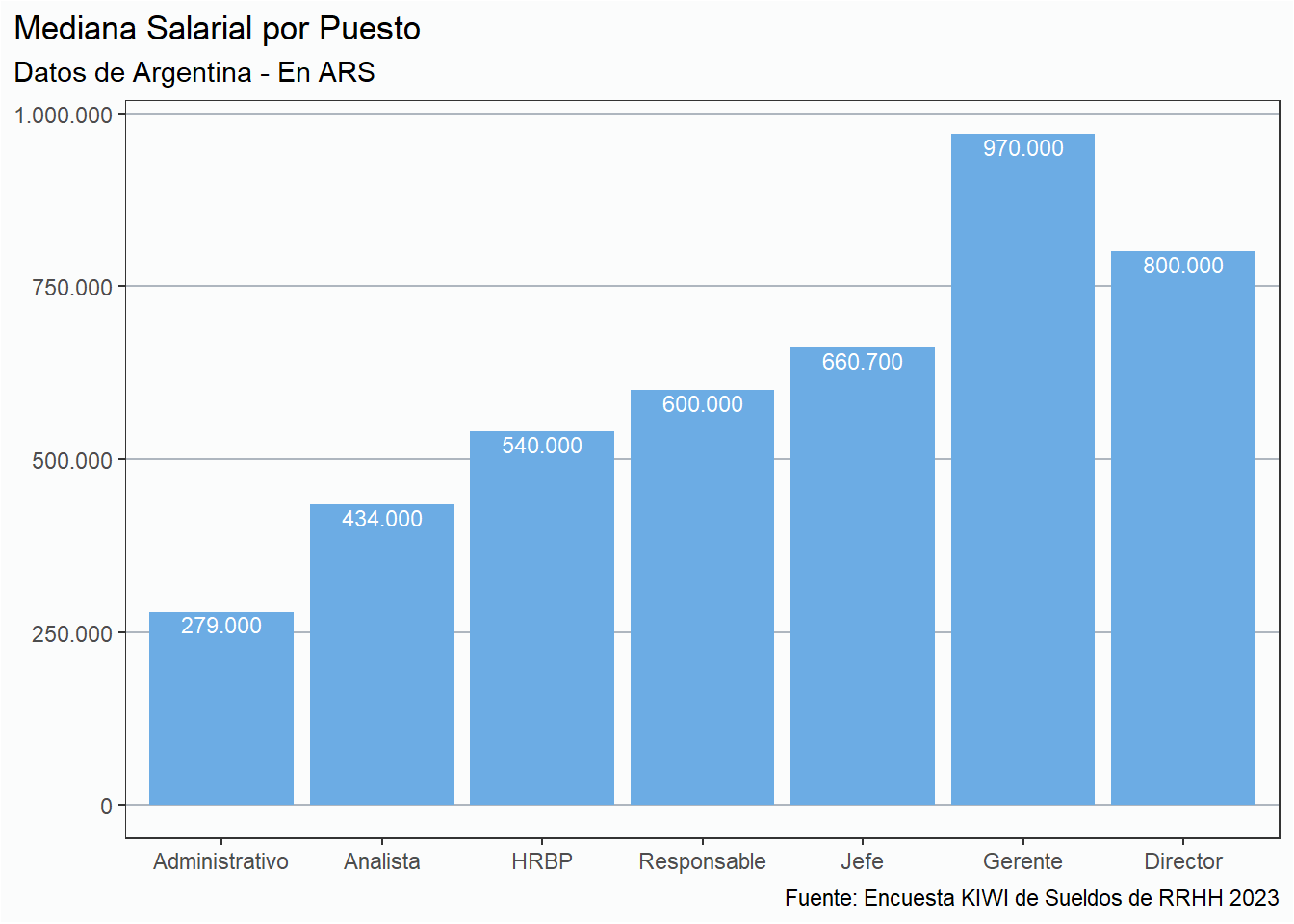
# Crear un data frame sólo con países de Latinoaméricarh23la <- rh23 %>%filter(pais !="España")# Gráficos de sueldo promedio por puestorh23la %>%select(puesto, sueldo_dolar) %>%filter(between(sueldo_dolar, poda_p05, poda_p95)) %>%group_by(puesto) %>%summarise(mediana_salarial =median(sueldo_dolar)) %>%ggplot(aes(x = mediana_salarial, y =fct_rev(puesto))) +geom_col(fill = azul) +geom_text(aes(label =comma(mediana_salarial, accuracy =1,prefix ="USS ",decimal.mark =",", big.mark =".")),color ="#FBFCFC",hjust =1.2,fontface ="bold",size =3) + estilov +labs(title ="Mediana salarial por puesto", subtitle ="Sueldos de RRHH en U$S", x ="", y ="", caption = fuente) + eje_x_n
La posición de HRBP presenta una complejidad, que es que dependiendo la empresa el rol es similar al de un Manager, o en otros casos es un Analista Especializado o Senior. Es por eso que encontramos entre los HRBP encontramos un suledo mínimo similar al de los analistas y salarios máximos mayores que el de los directores.
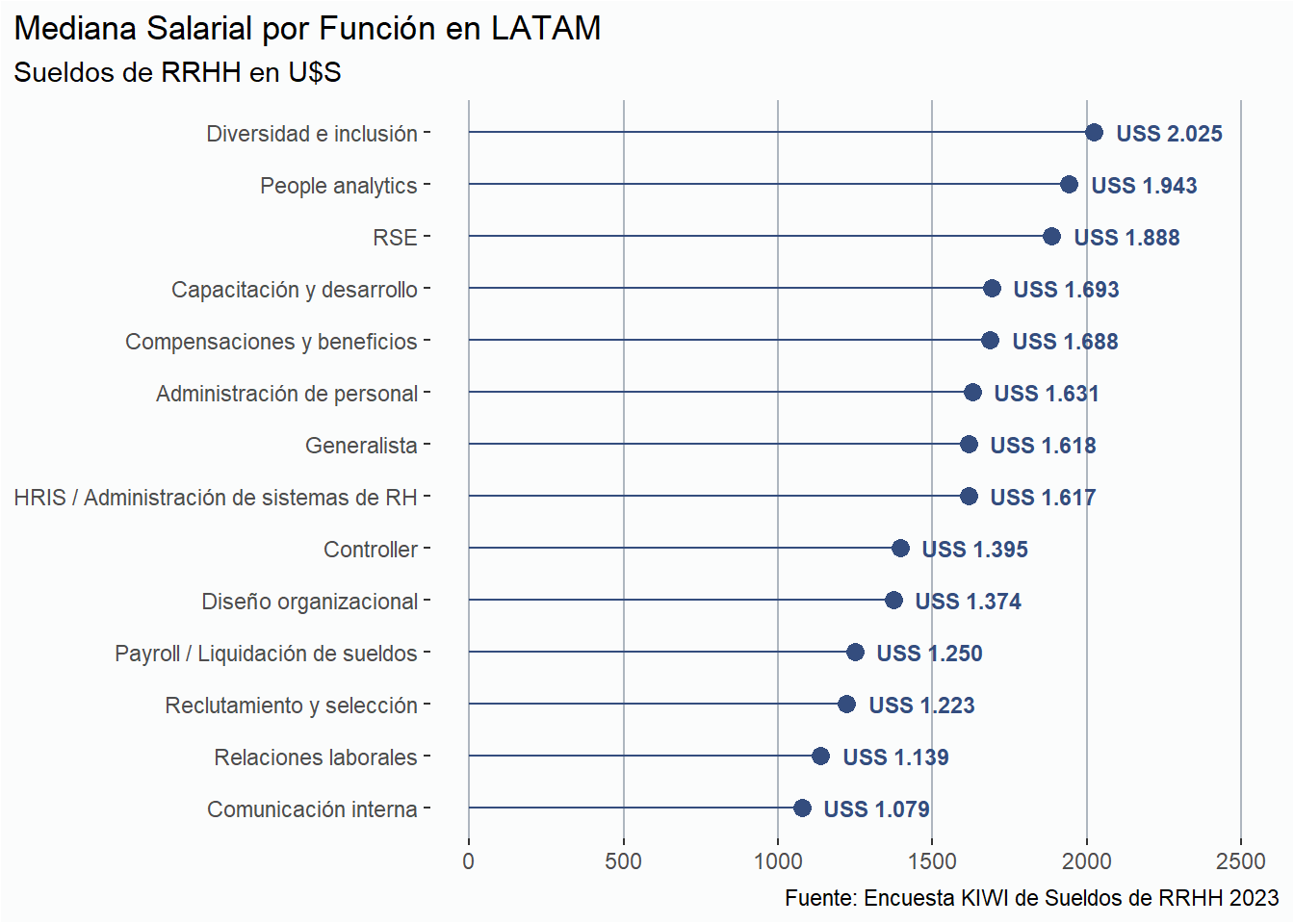
Entre las funciones mejor pagas, en esta edición encontrmos en el posio a Diversidad e Inclusión, People Analytics, y RSE cuentan con salarios más altos.
Nuevamente es necesario aclarar que hay funciones donde no tenemos mucha cantidad de respuestas como Controller donde sólo tenemos un solo caso, pero la diferencia entre las funciones con mayores sueldos, y con los menores sueldos es muy amplia (U$D 946).
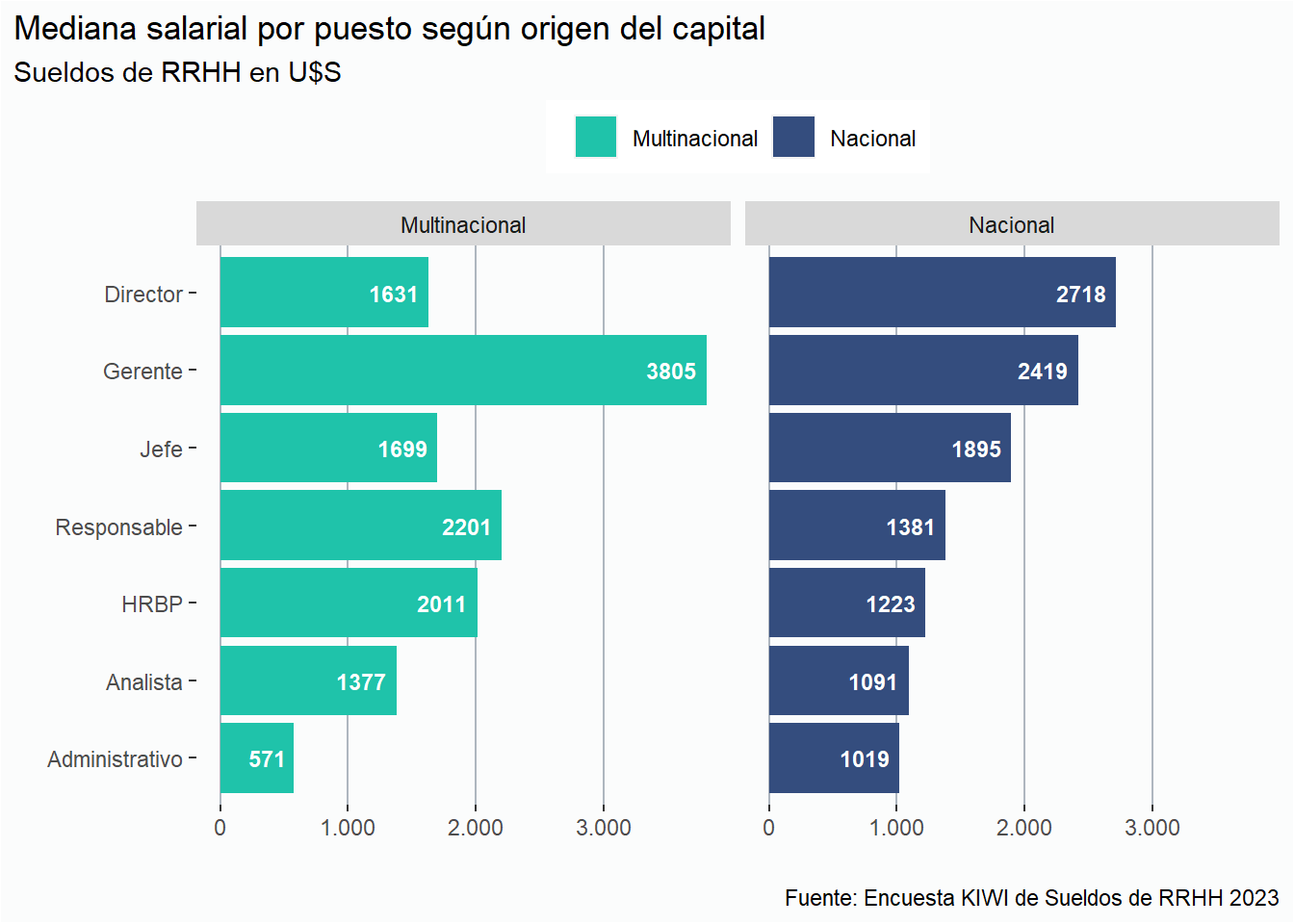
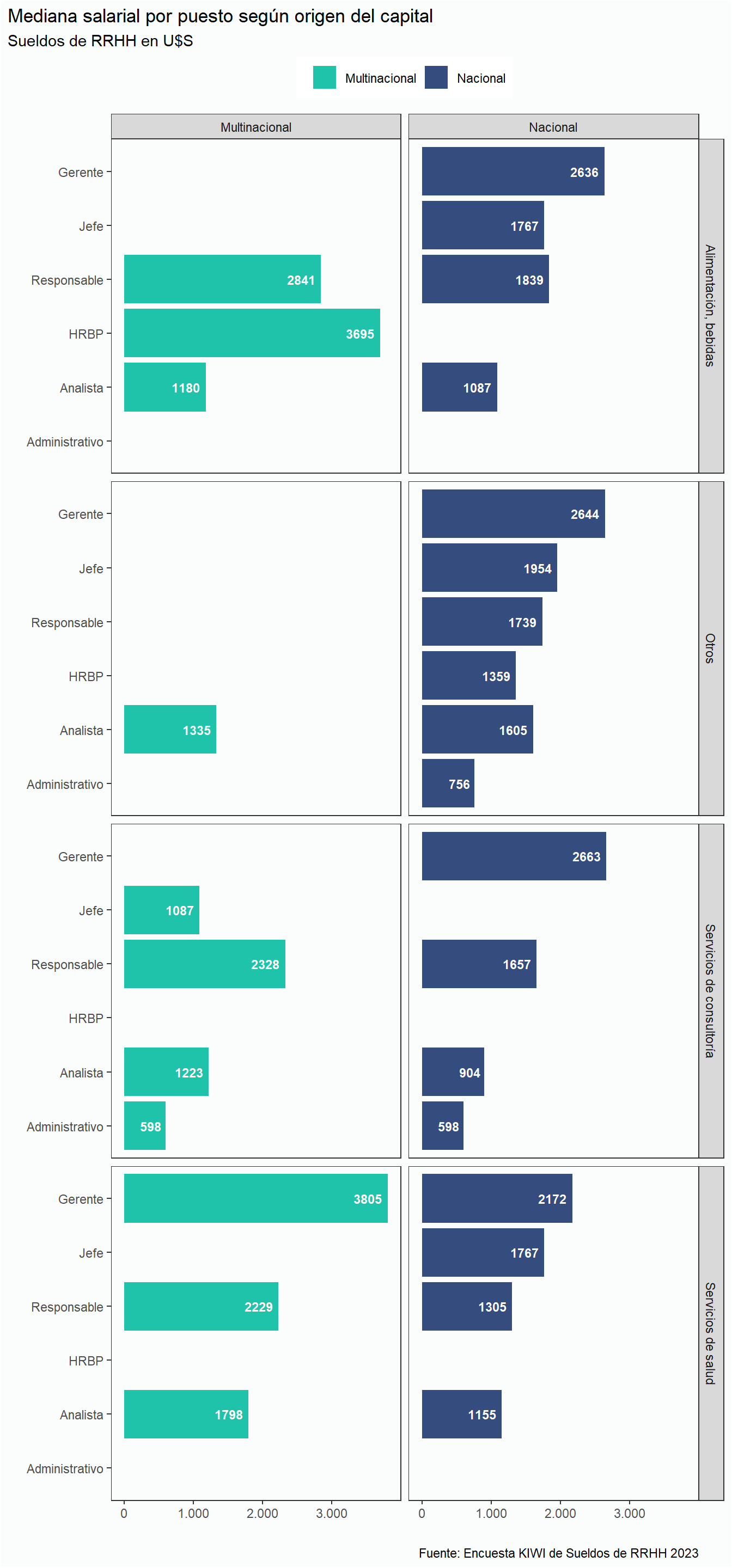
Si dividimos los gráficos según el Origen del Capital, podemos apreciar que en líneas generales, la mediana salarial en empresas multinaciones es mayor que en las empresas nacionales. Solamente en las posiciones de HRBP y de Gerente se aprecia una paridad salarial respecto del origen del capital de la organización.
Ver código
rh23la %>%select(origen_capital, puesto, sueldo_dolar) %>%filter(puesto !="Pasante", between(sueldo_dolar, poda_p05, poda_p95)) %>%group_by(puesto, origen_capital) %>%summarise(mediana_salarial =median(sueldo_dolar)) %>%ggplot(aes(x = mediana_salarial, y =fct_rev(puesto), fill = origen_capital)) +geom_col() +geom_text(aes(label =round(x=mediana_salarial, 0), hjust =1.2, fontface ="bold"),size =3, color ="white") +scale_fill_manual(values =c(verde, azul)) + estilov + eje_x_n +facet_wrap(~origen_capital) +labs(title ="Mediana salarial por puesto según origen del capital", subtitle ="Sueldos de RRHH en U$S", x ="", y ="", fill ="", caption = fuente) +theme(legend.position ="top")
Veamos este gráfico de otra manera:
Ver código
slope_df <- rh23la %>%select(puesto, sueldo_dolar, origen_capital) %>%filter(between(sueldo_dolar, poda_p05, poda_p95), puesto !="Pasante") %>%group_by(puesto, origen_capital) %>%summarise(mediana_salarial =round(median(sueldo_dolar)))CGPfunctions::newggslopegraph(dataframe = slope_df,Times = origen_capital,Measurement = mediana_salarial,Grouping = puesto,Title ="Diferencias entre sueldos de RRHH en empresas nacionales y multinacionales",SubTitle ="Mediana Salarial. Sueldos en U$S",Caption = fuente, WiderLabels = T)
Análisis por rubro y origen del capital
Para el análisis de los rubros de la empresa, vamos a filtrar los 5 rubros que tienen más respuestas. También eliminaremos del análisis el puesto de Director porque no se encuentra presente en todos los rubros.
Ver código
top_5_rubros <- rh23la %>%select(rubro) %>%group_by(rubro) %>%count(sort =TRUE) %>%filter(n >15) %>%pull(var = rubro)rh23la %>%mutate(rubro =str_wrap(rubro, width =25)) %>%select(rubro, origen_capital, puesto, sueldo_dolar) %>%filter(puesto !="Pasante", puesto !="Director",between(sueldo_dolar, poda_p05, poda_p95), rubro %in% top_5_rubros) %>%group_by(rubro, puesto, origen_capital) %>%summarise(mediana_salarial =median(sueldo_dolar)) %>%ggplot(aes(x = mediana_salarial, y =fct_rev(puesto), fill = origen_capital)) +geom_col() +geom_text(aes(label =round(x=mediana_salarial, 0), hjust =1.2, fontface ="bold"),size =3, color ="white") +scale_fill_manual(values =c(verde, azul)) + estilo + eje_x_n +facet_grid(rubro~origen_capital) +labs(title ="Mediana salarial por puesto según origen del capital", subtitle ="Sueldos de RRHH en U$S", x ="", y ="", fill ="", caption = fuente) +theme(legend.position ="top")
Para ver las medianas salariales por rubros junto con el desvío estándar, pueden ver la siguiente tabla:
Petróleo y producción de gas, refinación de petróleo
2011
925
5
Servicios profesionales
1958
796
4
Terminales automotrices, fábricas autopartistas, y afines
1889
837
4
Medios de comunicación, cultura, gráficos
1848
348
3
Otros
1651
922
32
Servicios de salud
1631
777
16
Servicios públicos (agua, gas, electricidad)
1579
NA
1
Industria siderúrgica
1576
NA
1
Construcción
1536
945
12
Servicios financieros seguros
1522
387
5
Ingeniería mecánica
1495
NA
1
Industrias químicas
1481
1106
7
Textiles, vestido, cuero, calzado
1451
966
4
Servicios de correos y de telecomunicaciones
1445
109
2
Alimentación, bebidas
1388
837
18
Comercio
1381
876
10
Agricultura, plantaciones, otros sectores rurales
1367
520
6
Tecnologías de información
1359
862
60
Servicios de consultoría
1181
826
28
Educación
1141
454
5
Transporte (incluyendo aviación civil, ferrocarriles por carretera)
1141
1010
5
Industria metalúrgica, metalmecánica
1091
419
6
Función pública
1060
566
5
Hotelería, restauración, turismo
929
697
3
Bancos, banca online
742
451
3
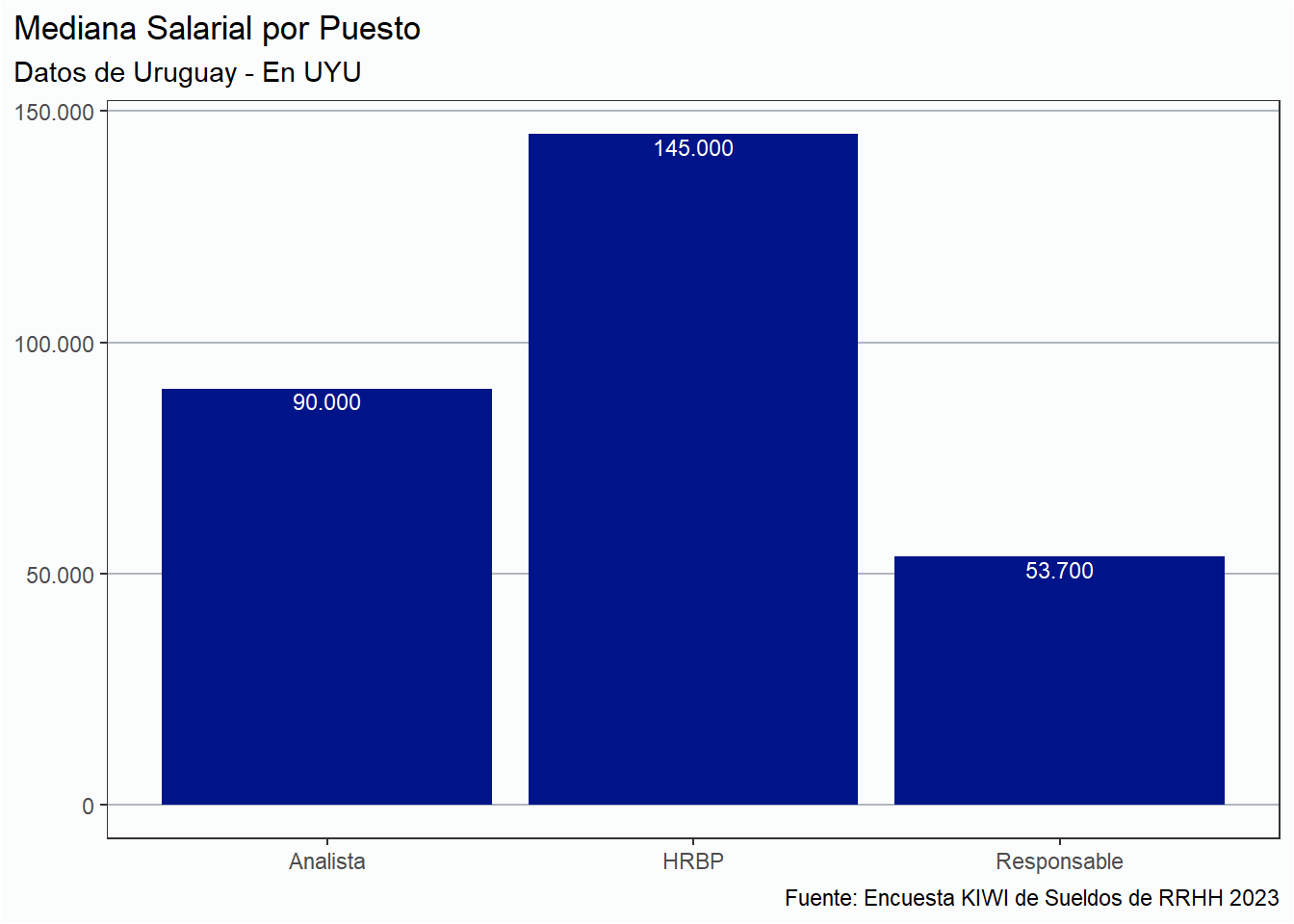
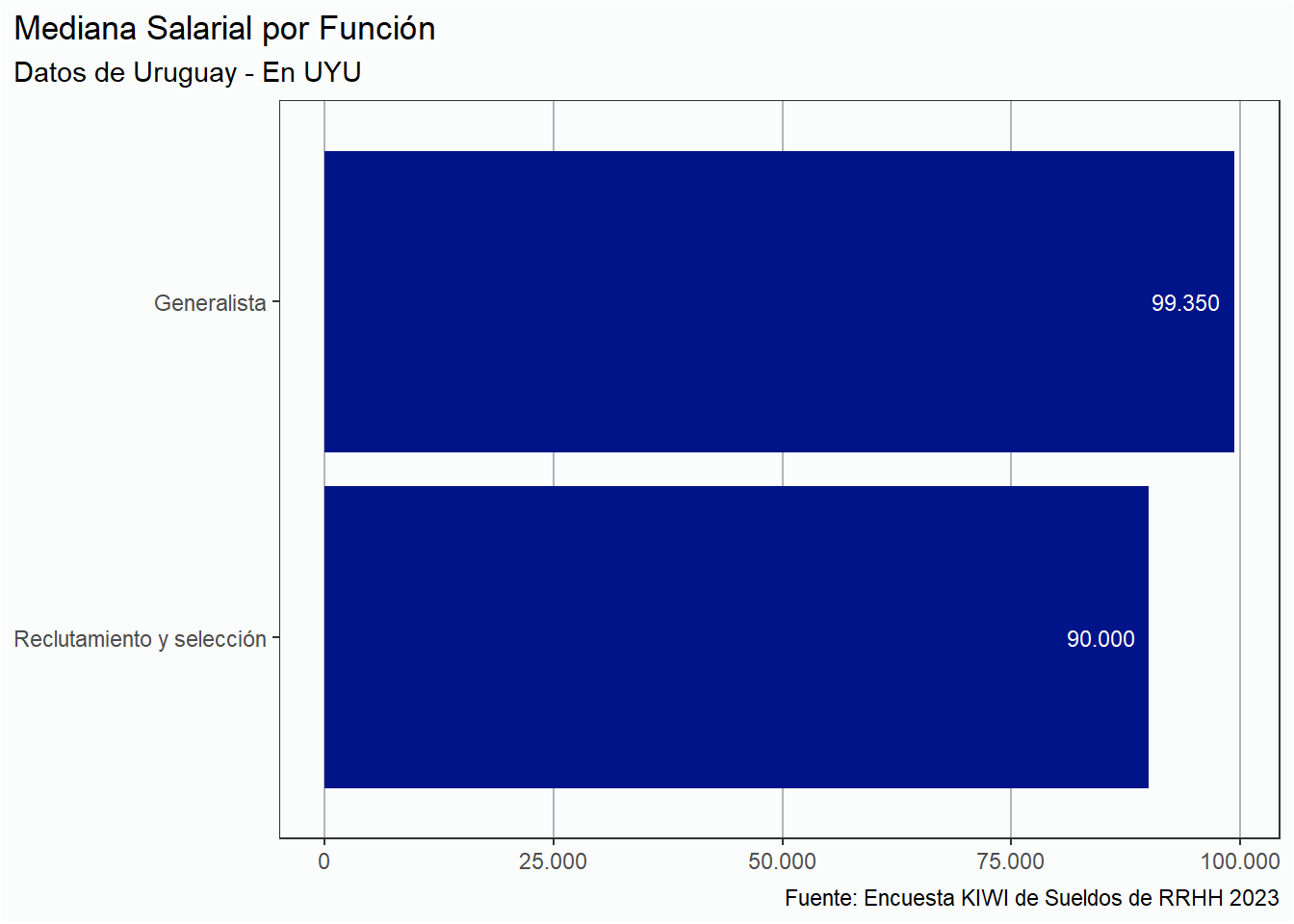
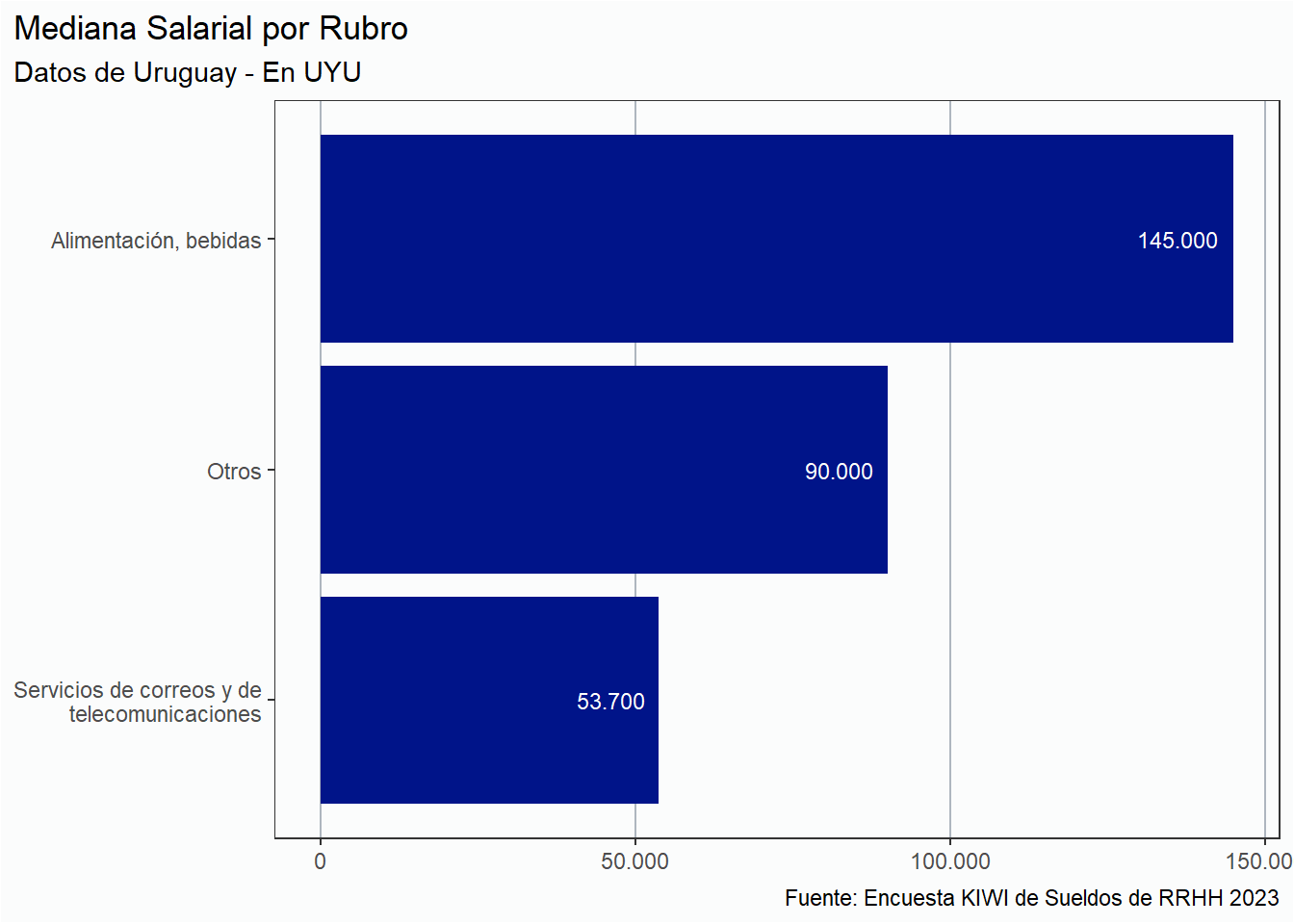
Análisis por países
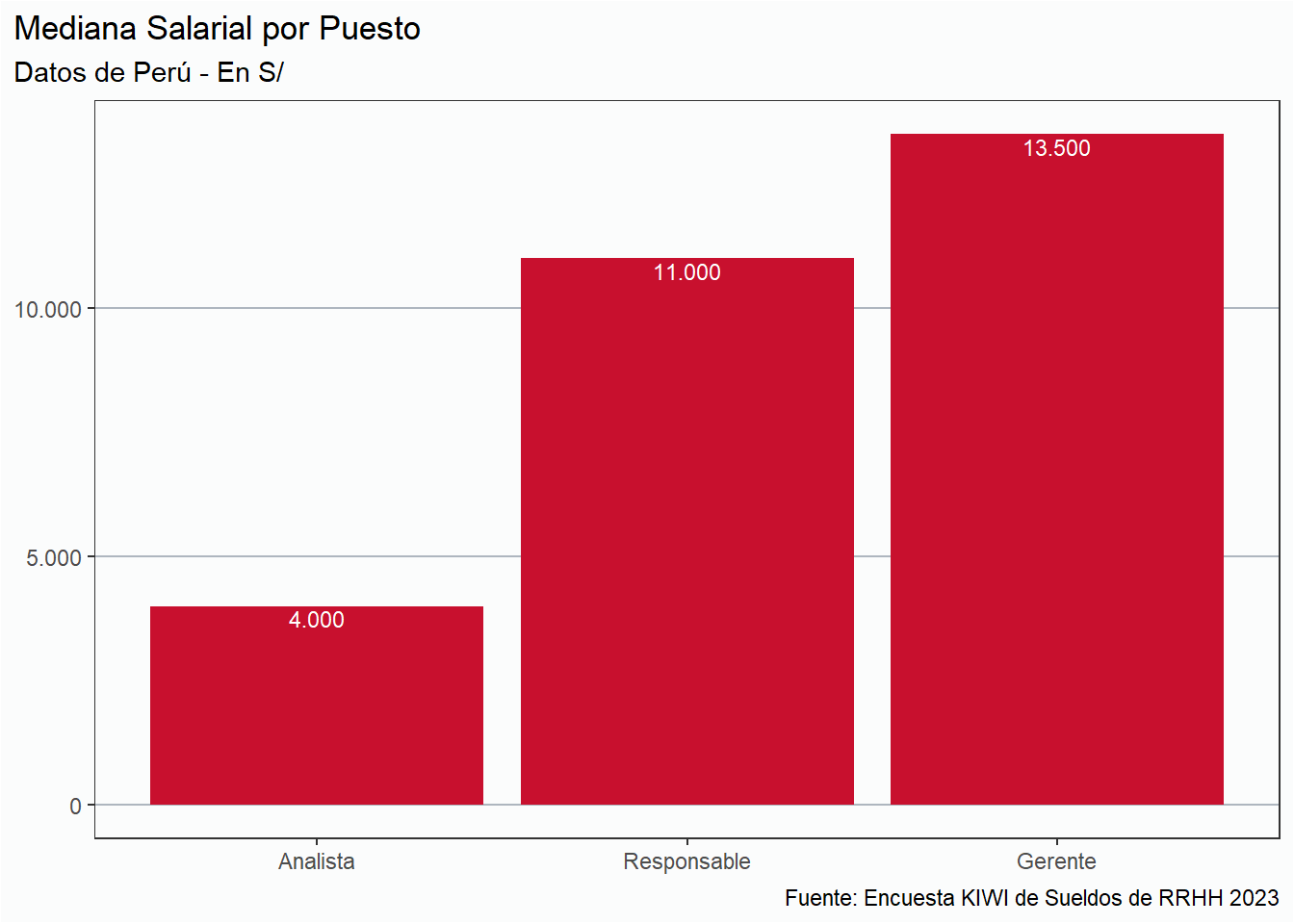
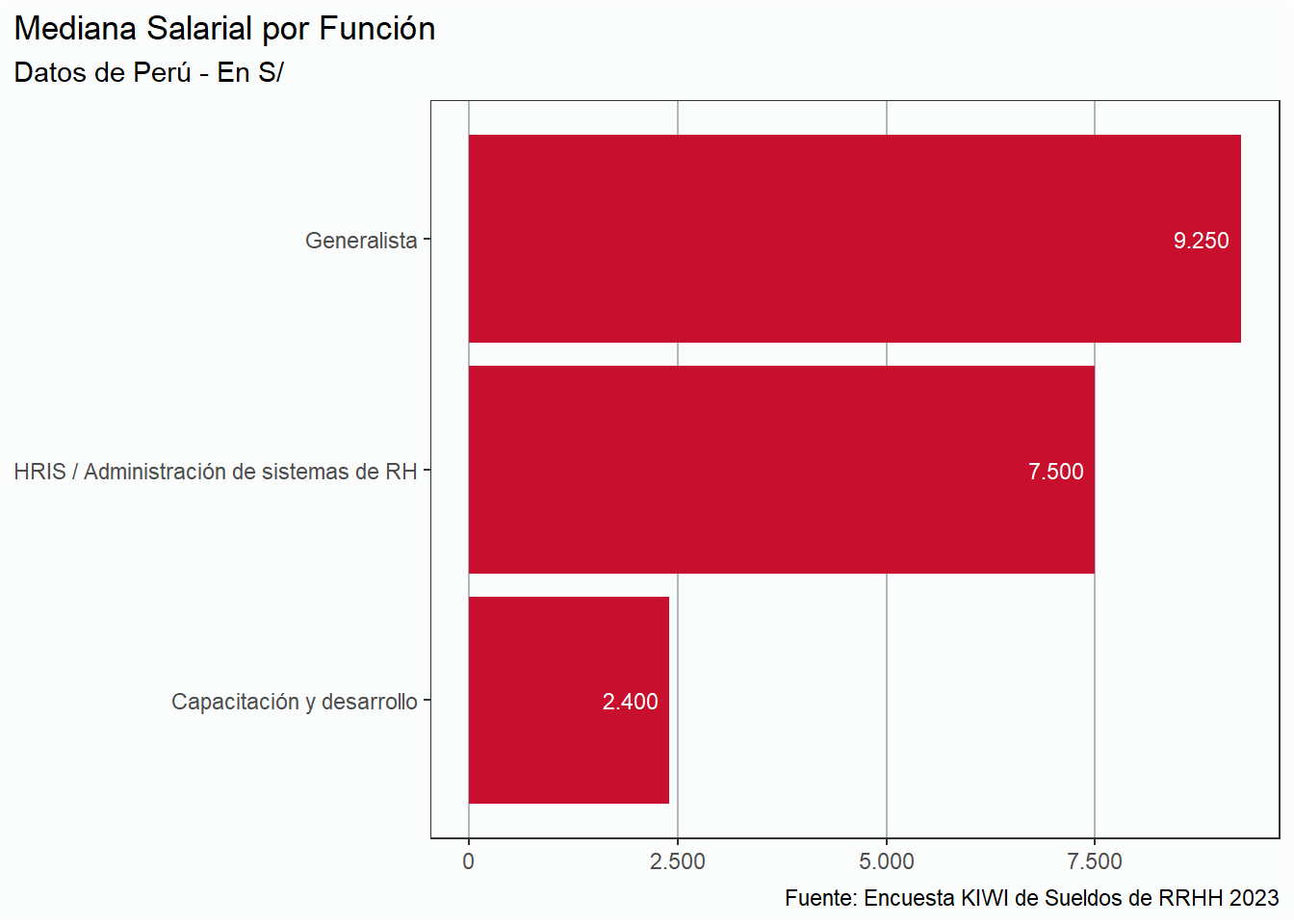
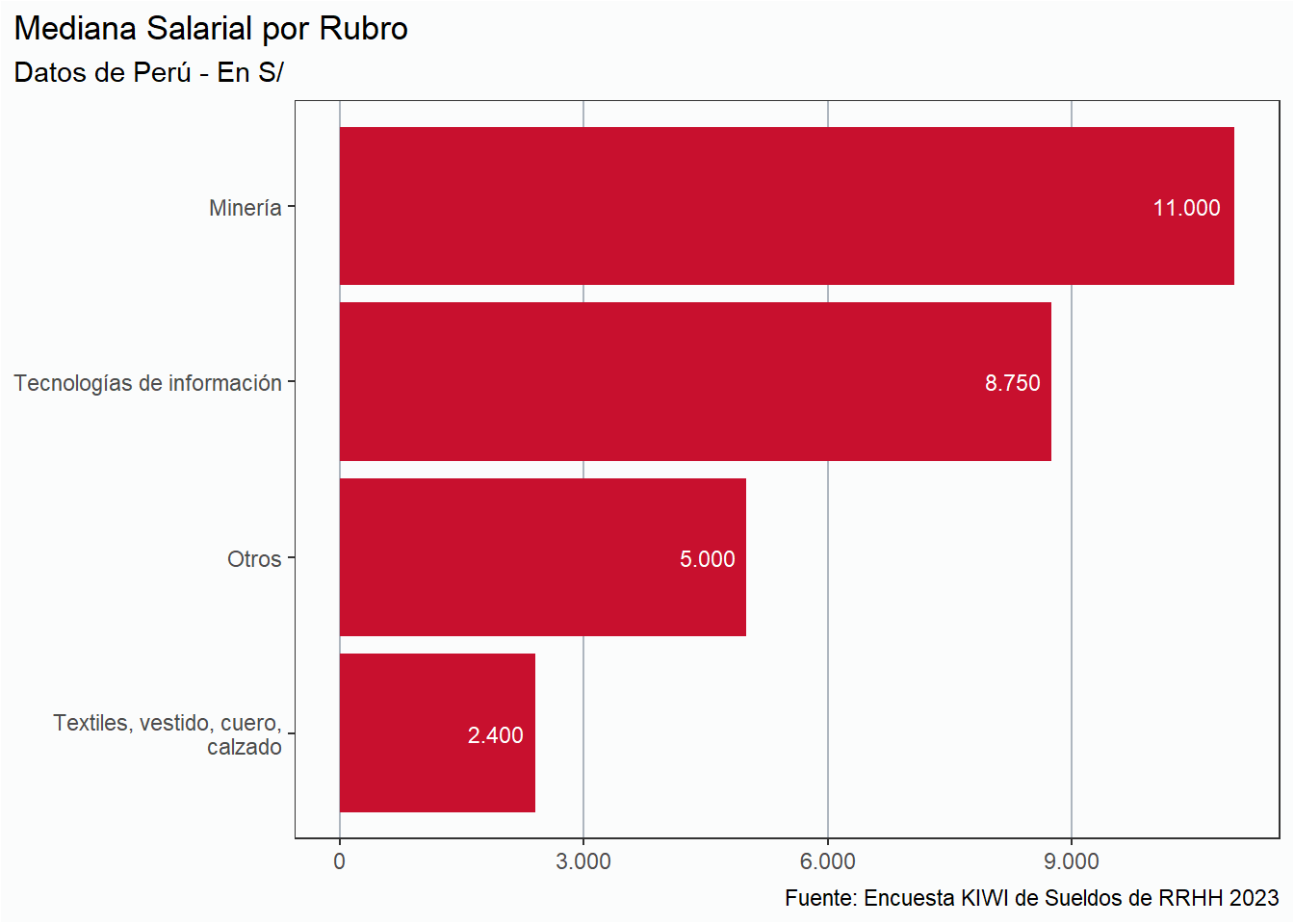
En esta sección analizaremos la situación salarial de RRHH únicamente de tres países: Argentina, Perú y Uruguay únicamente, por la cantidad de respuestas. Del resto de los países tenemos menos de 5 respuestas, por lo que es imposible realizar un análisis serio.
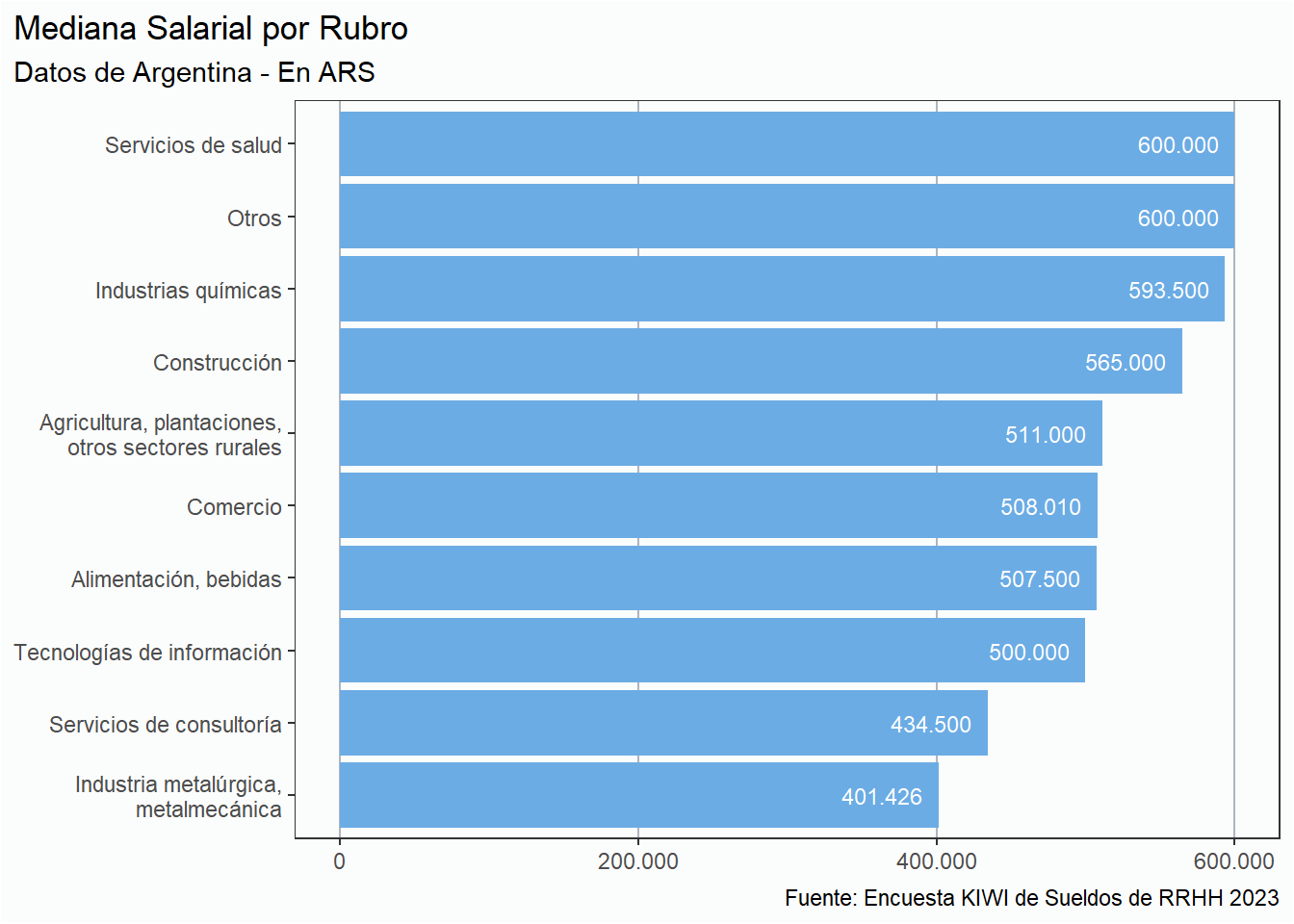
rh_ar %>%filter(rubro %in%c("Tecnologías de información", "Otros","Servicios de consultoría","Alimentación, bebidas","Servicios de salud", "Construcción","Comercio", "Industria metalúrgica,\nmetalmecánica","Industrias químicas","Agricultura, plantaciones,\notros sectores rurales" )) %>%group_by(rubro) %>%summarise(mediana =median(sueldo_bruto)) %>%ungroup() %>%ggplot(aes(y =reorder(rubro, mediana), x = mediana)) +geom_col(fill ="#6CACE4") +geom_text(aes(label =comma(mediana, big.mark =".", decimal.mark =",")),hjust =1.2,size =3, color ="white") + eje_x_n + estilov +labs(title ="Mediana Salarial por Rubro",subtitle ="Datos de Argentina - En ARS",x =NULL, y =NULL,caption = fuente)
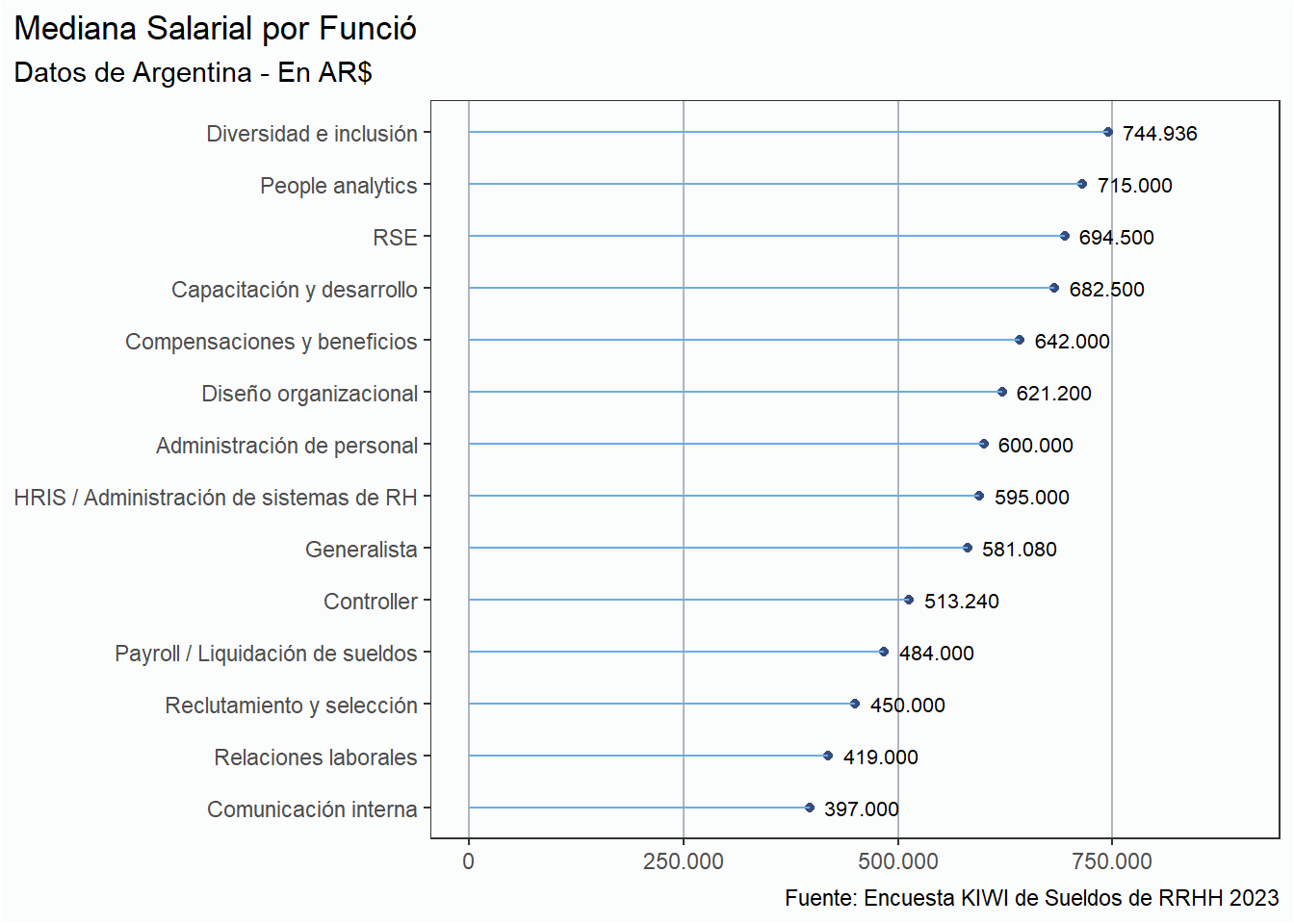
Sueldo por Función
Ver código
rh_ar %>%group_by(funcion) %>%summarise(mediana =median(sueldo_bruto)) %>%ungroup() %>%ggplot(aes(y =reorder(funcion, mediana), x = mediana)) +geom_point(color = azul) +geom_segment(aes(x =0, xend = mediana, y = funcion, yend = funcion), color ="#6CACE4") +geom_text(aes(label =comma(mediana, big.mark =".", decimal.mark =",")),hjust =-0.2,size =2.8) +scale_x_continuous(limits =c(0, 900000), labels =comma_format(big.mark =".",decimal.mark =";")) + estilov +labs(title ="Mediana Salarial por Funció",subtitle ="Datos de Argentina - En AR$",x =NULL, y =NULL,caption = fuente)
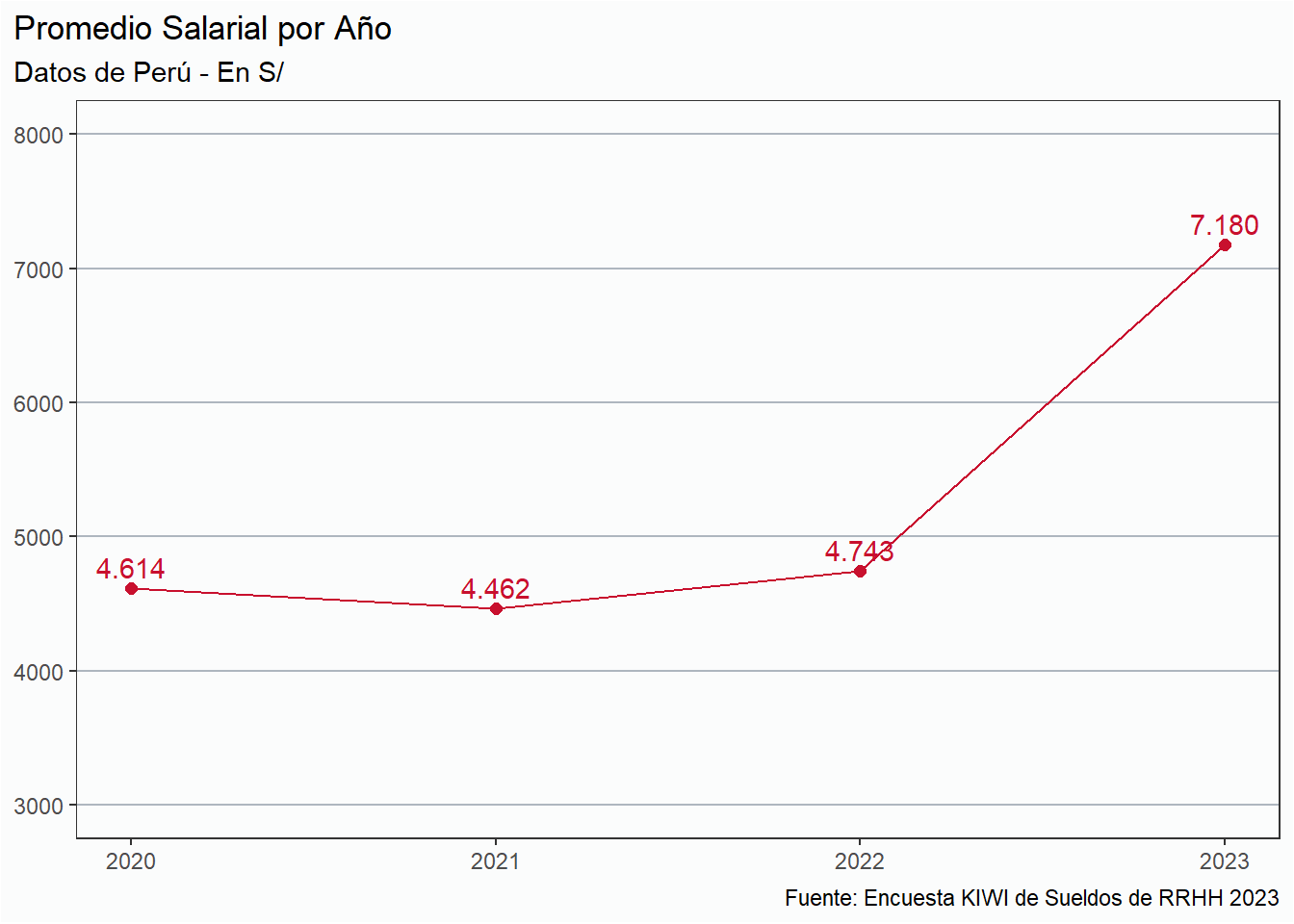
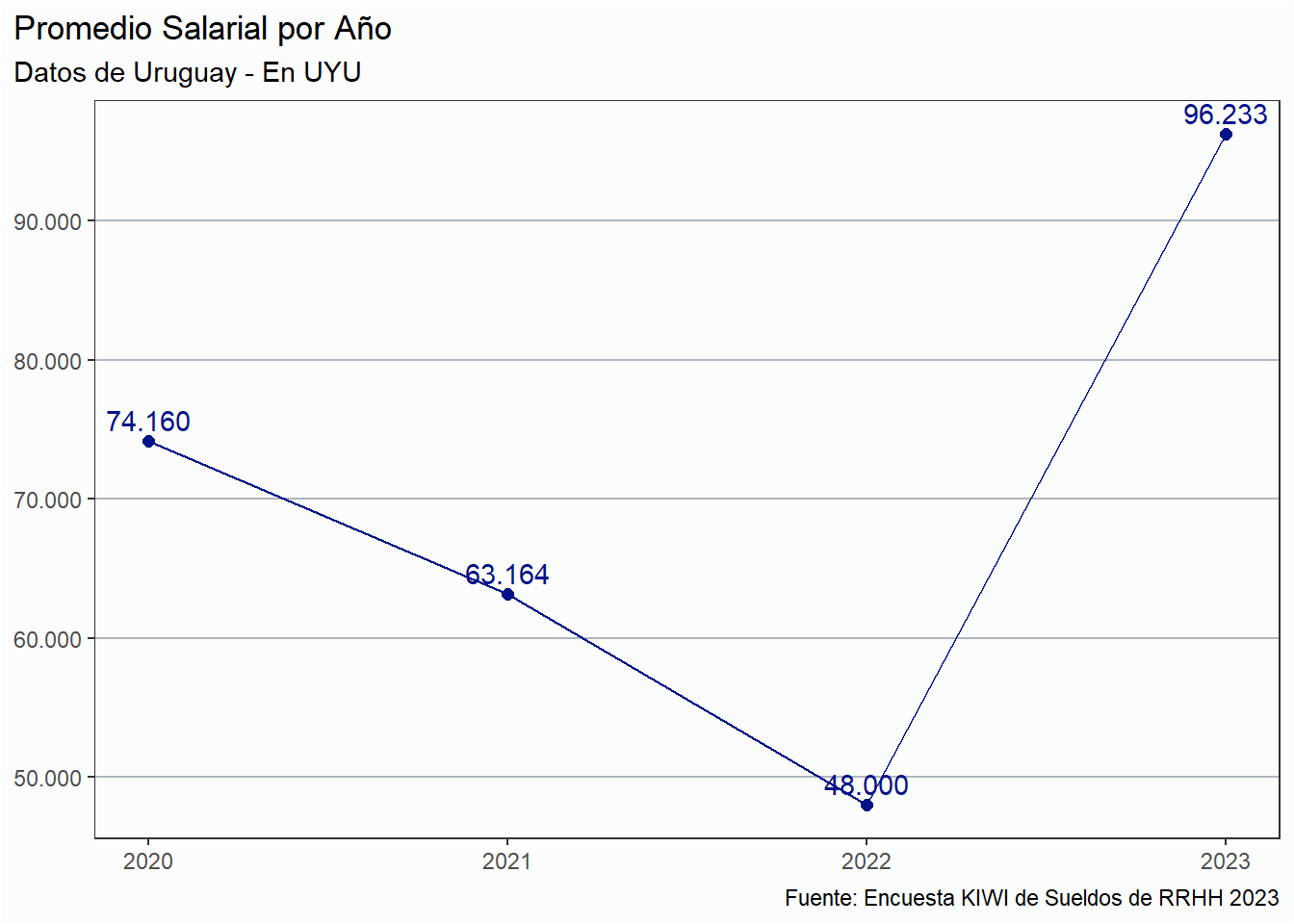
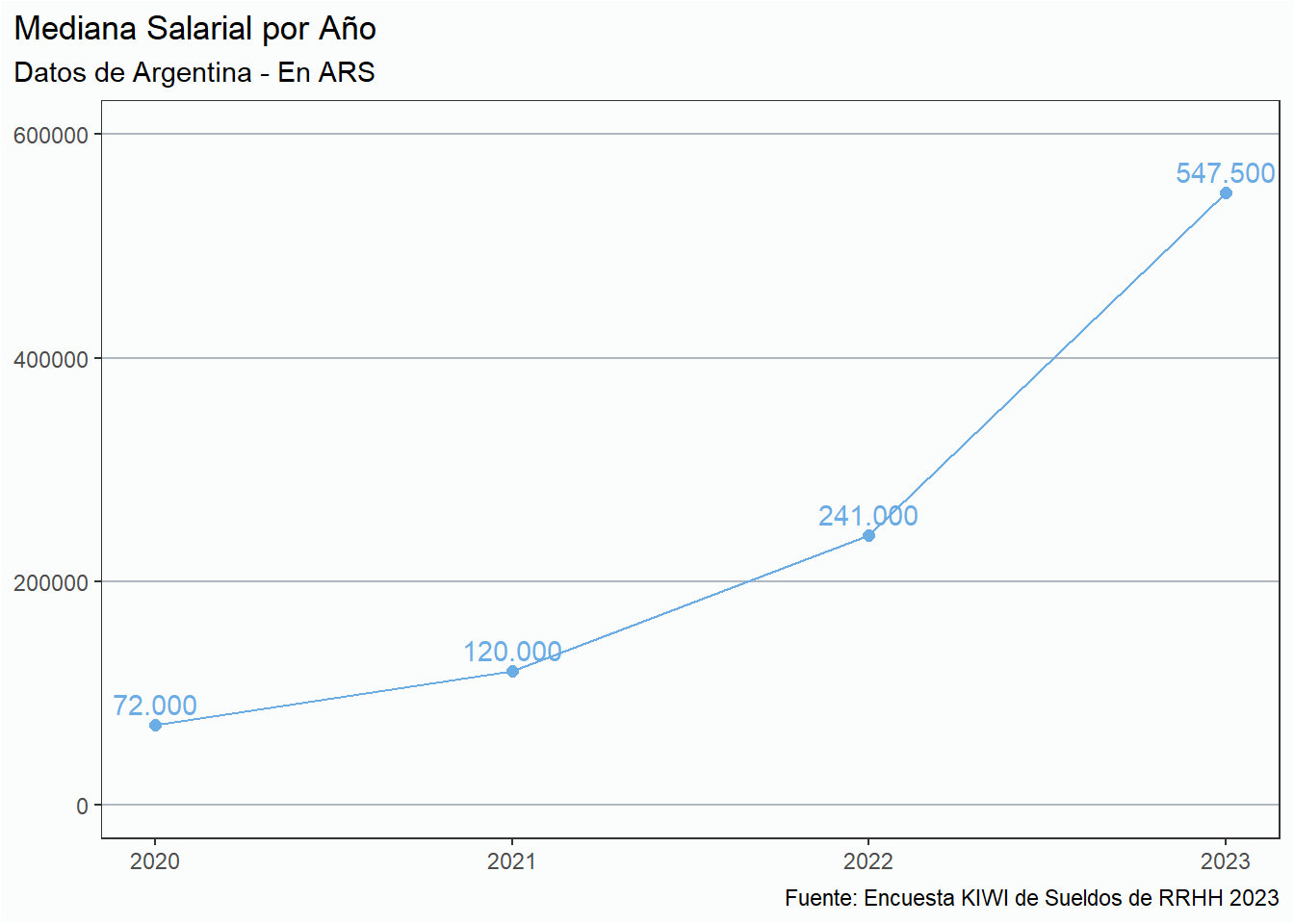
Evolución
La evolución de los salarios en moneda local puede ser contraintuitiva dada la baja cantidad de respuestas obtenidas por año.
Ver código
historico %>%group_by(anio) %>%summarise(mediana =median(sueldo_bruto)) %>% ungroup %>%ggplot(aes(x = anio, y = mediana, group =1)) +geom_line(color ="#6CACE4") +geom_point(color ="#6CACE4", size =2) +geom_text(aes(label =comma(mediana, big.mark =".", decimal.mark =",")),vjust =-0.5,color ="#6CACE4") + eje_y_n + estiloh +labs(title ="Mediana Salarial por Año",subtitle ="Datos de Argentina - En ARS",x =NULL, y =NULL,caption = fuente) +scale_y_continuous(limits =c(0, 600000))
Evolución por Función vs. Año Anterior
Ver código
historico %>%filter(anio %in%c(2022, 2023), funcion %in%c("HRIS / Administración de sistemas de RH","Generalista","Reclutamiento y selección","Administración de personal","Payroll / Liquidación de sueldos","Capacitación y desarrollo","People analytics","HRIS / Administración de sistemas de RH","Comunicación interna","Compensaciones y beneficios","Diseño organizacional","Relaciones laborales")) %>%group_by(funcion, anio) %>%summarise(mediana =median(sueldo_bruto)) %>% ungroup %>%ggplot(aes(y =fct_rev(funcion), x = mediana, fill =factor(anio))) +geom_col(position ="dodge") +geom_text(aes(label =comma(mediana, big.mark =".", decimal.mark =",")),position =position_dodge(0.9),hjust =1.2,size =2, color ="white") +theme(legend.position ="top") +guides(fill =guide_legend(reverse=TRUE)) +scale_fill_manual(values =c(gris, "#6CACE4")) + estilov + eje_x_n +labs(title ="Evolución Salarial por Función",subtitle ="En AR$",x =NULL, y =NULL,caption = fuente,fill ="Año")
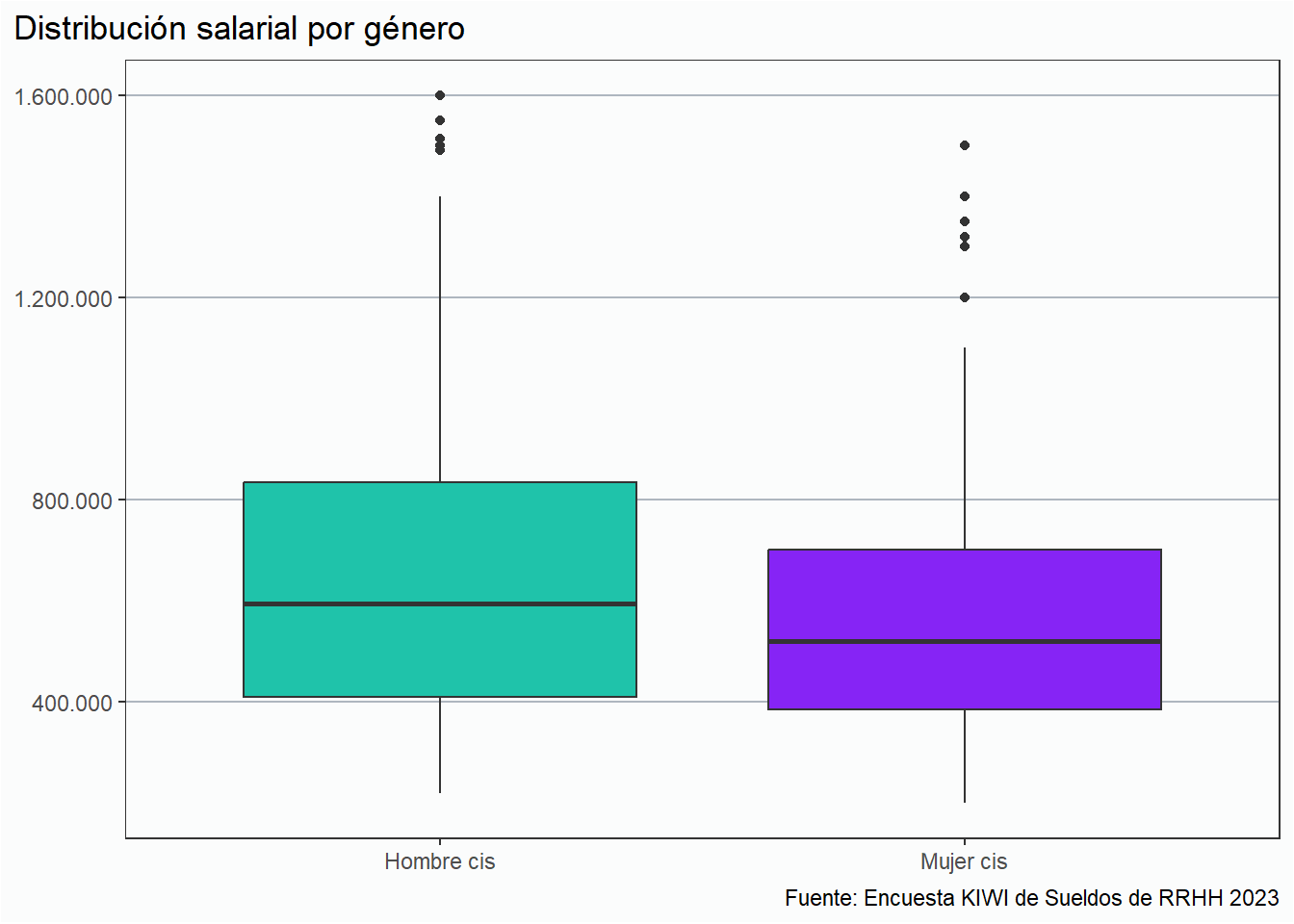
Comparación salarial por género
En el gráfico a continuación podemos apreciar que los hombres cis tienen sueldos más altos que las mujeres cis.
Ver código
rh_ar %>%filter(genero %in%c("Hombre cis", "Mujer cis")) %>%ggplot(aes(x = genero, y = sueldo_ft, fill = genero)) +geom_boxplot() + eje_y_n +scale_fill_manual(values =c(verde, lila)) + estiloh +labs(title ="Distribución salarial por género",x =NULL, y =NULL,fill ="Género", caption = fuente) +theme(legend.position ="none")
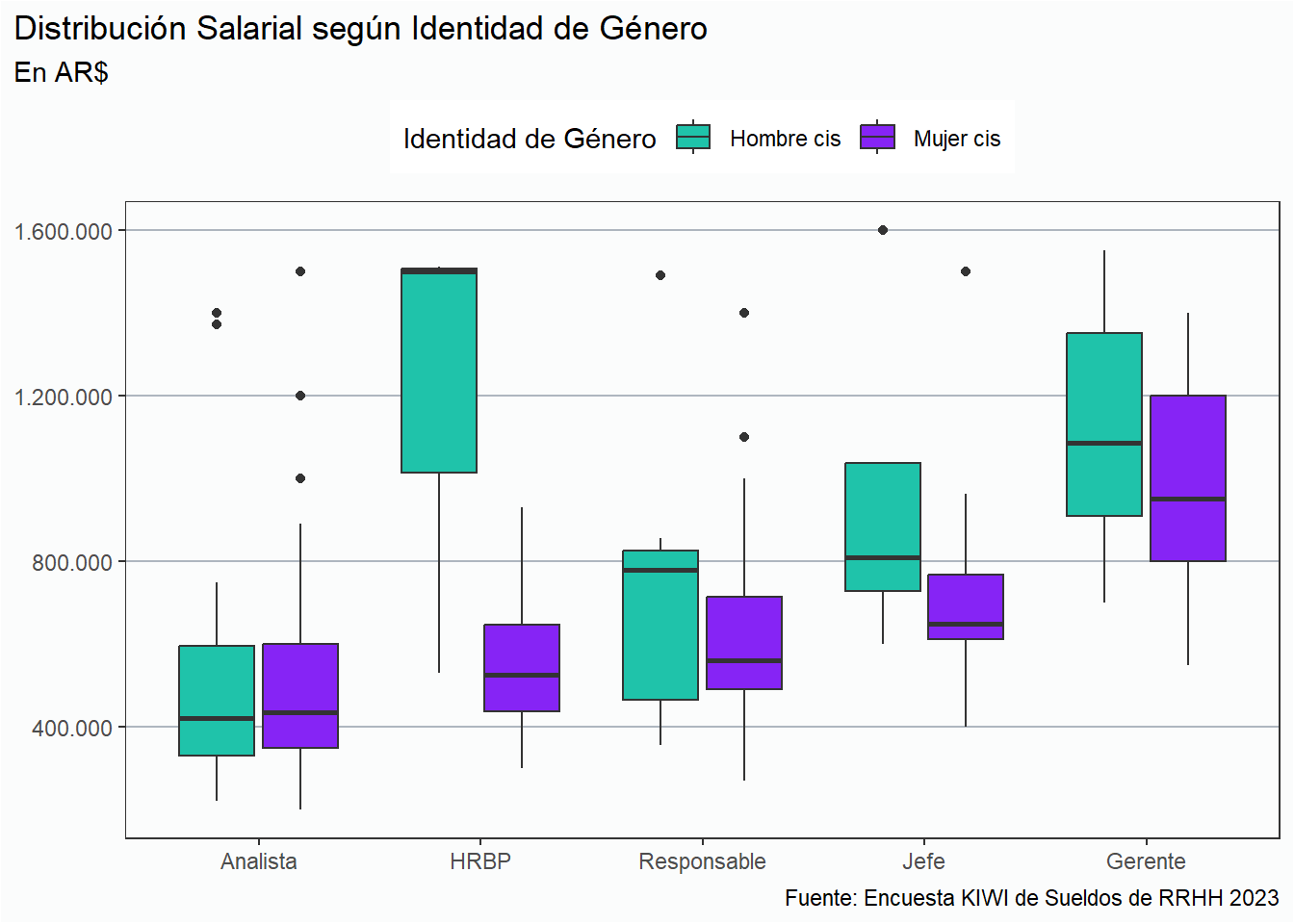
Análisis por Género y Puesto
Cuando analizamos la distribución salarial por puesto, apreciamos desigualdades que se repiten de años anteriores. Antes de profundizar, expliquemos brevemente cómo interpretar el gráfico que vemos a continuación que se llama boxplot.
En primer lugar, la parte inferior de cada caja indica el valor del primer cuartil, es decir el límite donde se encuentra el 25% de los datos. Por otra parte, la parte superior de cada caja indica el tercer cuartil, o sea, el 75% de los datos. Esto implica que dentro de la caja nos encontramos con la mitad de los datos. La cantidad de casos dentro de cada mitad es la misma para cada caja.
Un elemento muy importante dentro del gráfico es la línea que observamos dentro de cada caja que representa a la mediana que es el valor que divide a la mitad a los datos. Este es el valor que habitualmente utilizamos para comparar salarios porque representa el punto medio para cada grupo y además no es sensible a valores extremos como el promedio. La mediana es el valor que vamos a usar para comparar los sueldos entre hombres y mujeres.
Los puntos que observamos en algunos casos indican valores extremos que denominamos outliers. Estos valores son atípicos. Las líneas que salen de las cajas indican los límites a partir de los cuales se determina que un valor es atípico o no.
Por último, el tamaño de la caja también es importante porque nos da una idea de la distribución de los datos. Si la caja es chiquita quiere decir que los sueldos están en un rango de valores cercano. En cambio si la caja, o una de sus mitades, es larga, eso nos indica que los sueldos tienen un rango más amplio, o sea que los sueldos llegan a valores más altos o más bajos dependiendo el caso, y que se alejan más de la mediana.
Ver código
rh_ar %>%filter(genero %in%c("Hombre cis", "Mujer cis"),!puesto %in%c("Director", "Administrativo")) %>%ggplot(aes(x =fct_rev(puesto), y = sueldo_bruto, fill = genero)) +geom_boxplot() + estiloh +scale_fill_manual(values =c(verde, lila)) + eje_y_n +labs(title ="Distribución Salarial según Identidad de Género",subtitle ="En AR$",fill ="Identidad de Género",x =NULL, y =NULL,caption = fuente) +theme(legend.position ="top")
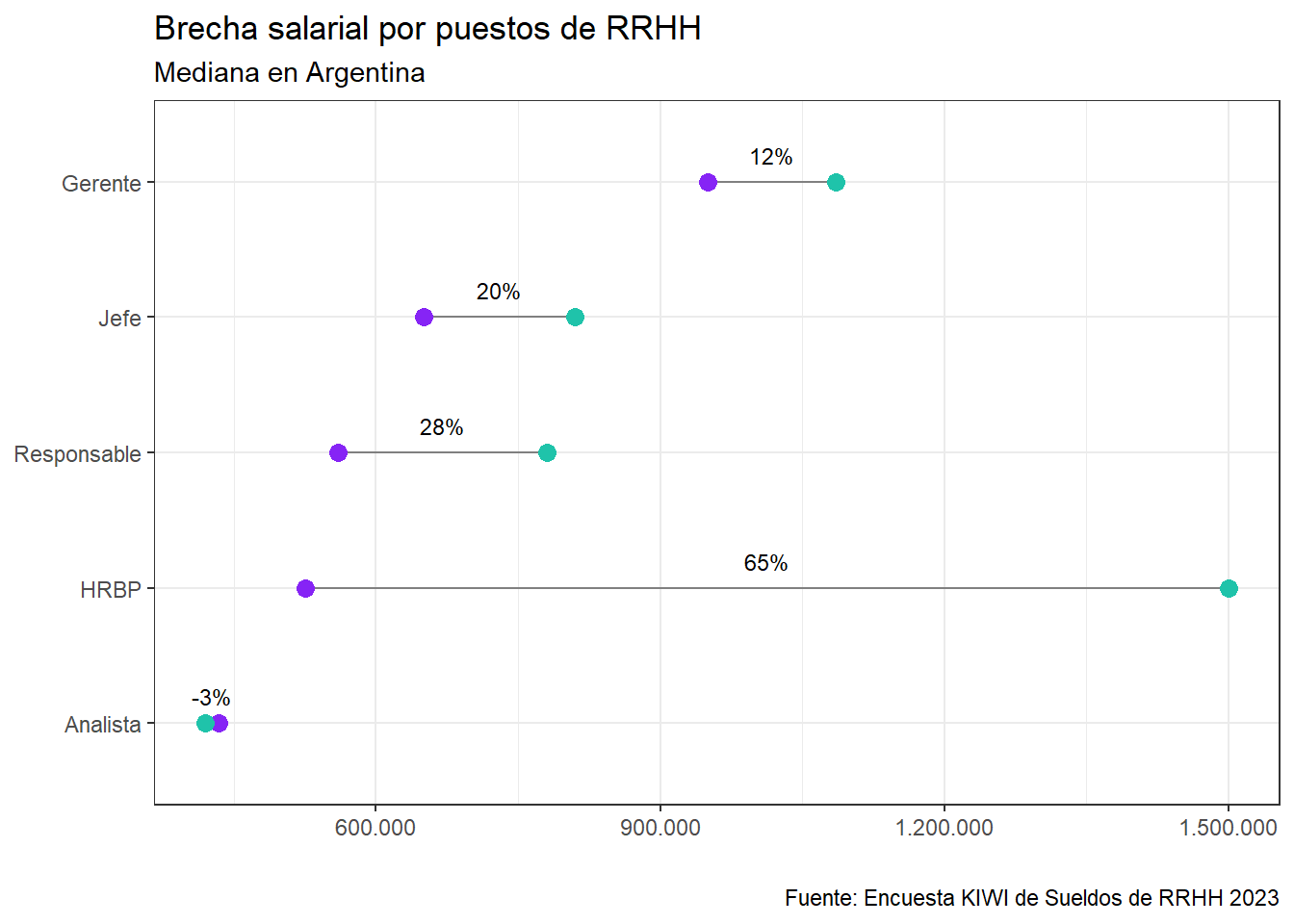
En el gráfico a continuación podemos apreciar la brecha salarial comparando la mediana salarial para hombres y mujeres en cada posición.
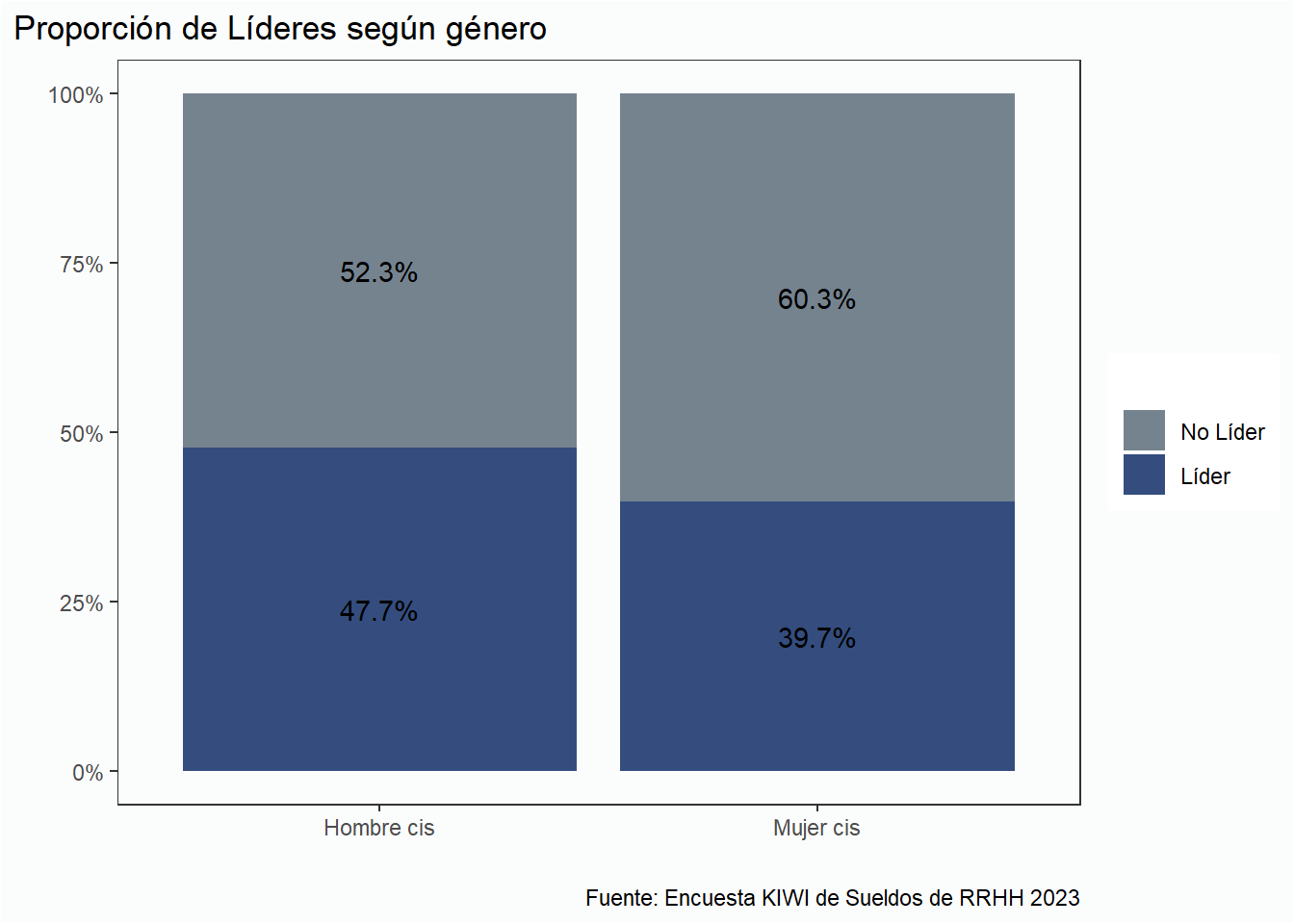
Analicemos las proporciones de hombres y de mujeres en puesto de liderazgo.
Ver código
#|label: Test hipotesis liderazgo#| results: hidediv <- rh23la %>%filter(pais =="Argentina") %>%select(genero) %>%mutate(genero =factor(genero, levels =c("Mujer cis", "Hombre cis"))) %>%group_by(genero) %>%summarise (n =n()) %>%mutate(freq = n/sum(n)) %>%arrange(-n)lideres <- rh23la %>%filter(pais =="Argentina") %>%select(genero, puesto) # Propoción de líderes hombres y mujereslideres_genero <- lideres %>%filter(genero %in%c("Mujer cis", "Hombre cis")) %>%group_by(genero) %>%mutate(gente_a_cargo =if_else(puesto %in%c("Responsable", "Jefe", "Gerente", "Supervisor", "Director"),1,0)) %>%summarise(lider =sum(gente_a_cargo)) %>%left_join(div) %>%select(genero, lider, n) %>%mutate(proporcion =percent(lider/n))# Test de hipótesis para validar diferencias de resultados# Hay que verificar si la proporción de líderes hombres es mayor que la proporción de líderes mujeres# Creo un dataframe para analizar proporciones de hombres y de mujeres en puestos de liderazgo y de no-liderazgotest_lider <- lideres_genero %>%mutate(no_lider = n - lider) %>%# Columna de no líderesselect(genero, lider, no_lider) %>%# selecciono columnas de interéspivot_longer(cols =c(lider, no_lider), # Hago un dataset largo para analizar despuésnames_to ="es_lider", values_to ="conteo")# Del total de respuestas me interesa sólo ver cuáles son los hombres con puesto de liderazgotest_lider$cat <-c(0,0,1,0)# Extraigo el mu para decidir si la diferencia es significativa y pasarlo a la fórmula del test.prop_mujer_lid <-pull(lideres_genero[1,2]/lideres_genero[1,3])# Realizo el test de hipótesis.# H0 = Las proporciones de líderes hombres y mujeres son iguales# H1 = La proporción de hombres líderes es mayor que la proporción de mujeres líderes.resultados_test <- broom::tidy(t.test(test_lider$cat, mu = prop_mujer_lid, alternative ="greater"))valor_test <-if(resultados_test[1,3] >0.05) {print("la diferencia es estadísticamente significativa, y la proporción de hombres en puestos de liderazgo es mayor que el de las mujeres") } else {print("la diferencia no es estadísticamente significativa, y la proporción de hombres no es estadísticamente mayor que el de las mujeres en puestos de liderazgo") }
[1] "la diferencia es estadísticamente significativa, y la proporción de hombres en puestos de liderazgo es mayor que el de las mujeres"
Ver código
# Gráficolideres_genero %>%mutate(porc_lider = lider/n, porc_no_lider =1- porc_lider) %>%pivot_longer(cols =c(porc_lider, porc_no_lider),names_to ="es_lider", values_to ="valores") %>%mutate(es_lider =factor(es_lider, levels =c("porc_no_lider", "porc_lider"), labels =c("No Líder", "Líder"))) %>%ggplot(aes(x= genero, y = valores, fill = es_lider))+geom_col(position ="fill")+ estilo + eje_y_p +scale_fill_manual(values =c(gris, azul)) +labs(title ="Proporción de Líderes según género",x ="", y ="", fill ="", caption = fuente) +geom_text(aes(label =percent(valores)),position =position_stack(vjust =0.5))
De acuerdo a las respuestas recolectadas 2 de cada 3 participantes son mujeres.
Para los puestos de liderazgo consideramos las personas en los puestos de Director, Gerente, Jefe, y Responsable.
Del total de mujeres, 189 respuestas, 75 ocupan un puesto de liderazgo (39.7%).
Del total de hombres, 65 respuestas, 31 ocupan un puesto de liderazgo (47.7%).
Con un p-value igual a 0.785 podemos afirmar que la diferencia es estadísticamente significativa, y la proporción de hombres en puestos de liderazgo es mayor que el de las mujeres.
A pesar de que en Recursos Humanos en Argentina, las mujeres cis representan la mayor cantidad de empleados bajo relación de dependencia, y además se forman en mayor proporción que los varones en posgrados, proporcionalmente en comparación con los hombres cis, acceden a menos posiciones de liderazgo.
Diversidad en RRHH
Ver código
# Cargar los datos 2020 y 2021k20 <- googlesheets4::read_sheet("1833xEeRIy1DLke4eHKfEThjjgx01YGX9yQaU6vv15K0", skip =5) %>% janitor::clean_names()k21 <- googlesheets4::read_sheet("1LDdXlIwrcsyuywbcS4gdc-1p6wBXfEfL2Y6sNBj-4GM",skip =5) %>% janitor::clean_names()k22 <- googlesheets4::read_sheet("1KeB-sXRMmDhzgEPWLDVNUHgpgroVNsLO2UWE0RLLCVw",skip =5) %>% janitor::clean_names()# Seleccionar las columnas de ambos data frames.k20 <- k20 %>%select(identidad_genero = genero, diversidad_sexual = te_identificas_como_lgbt_lesbiana_gay_bisexual_transexual_otra_minoria_sexual,rubro = rubro_de_la_empresa, origen_del_capital,puesto = en_que_puesto_trabajas,nivel_formacion = maximo_nivel_de_formacion, discapacidad, trabajo) %>%mutate(sufrio_acoso =99,management_femenino =99,machismo =99,edicion =2020) # Añado una columna con un valor = 1 porque esta pregunta no existía en la edición 2020 de la Encuestak21 <- k21 %>%select(identidad_genero = identidad_de_genero,diversidad_sexual = te_identificas_como_lgbtiq_lesbiana_gay_bisexual_transexual_otra_minoria_sexual,rubro = rubro_de_la_empresa, origen_del_capital,puesto = en_que_puesto_trabajas,nivel_formacion = maximo_nivel_de_formacion,discapacidad = tenes_alguna_discapacidad, trabajo,sufrio_acoso = sufriste_alguna_situacion_de_acoso_abuso_o_de_discriminacion_en_algun_trabajo,management_femenino = que_porcentaje_aproximado_del_management_de_tu_empresa_son_mujeres_entiendase_posiciones_de_jefatura_de_gerencia_o_de_direccion) %>%mutate(machismo =99,edicion =2021)k22 <- k22 %>%select(identidad_genero = identidad_de_genero,diversidad_sexual = te_identificas_como_lgbtiq_lesbiana_gay_bisexual_transexual_otra_minoria_sexual,rubro = rubro_de_la_empresa, origen_del_capital,puesto = en_que_puesto_trabajas ,nivel_formacion = maximo_nivel_de_formacion,discapacidad = en_lo_que_va_del_ano_han_contratado_en_tu_empresa_a_personas_con_discapacidad , trabajo,sufrio_acoso = sufriste_alguna_situacion_de_acoso_abuso_o_de_discriminacion_en_algun_trabajo,management_femenino = que_porcentaje_aproximado_del_management_de_tu_empresa_son_mujeres_entiendase_posiciones_de_jefatura_de_gerencia_o_de_direccion,machismo = sentis_que_tu_entorno_laboral_es_machista) %>%mutate(edicion =2022)k23 <- kiwi %>%select(identidad_genero = genero, diversidad_sexual, rubro,origen_del_capital = origen_capital, puesto, nivel_formacion, discapacidad, trabajo, sufrio_acoso,management_femenino = diversidad_management, machismo) %>%mutate(edicion =2023)# Unir los dataframes en uno sólodiv_rh <-rbind(k20, k21, k22, k23)# Como ya tengo unificados ambos datasets puedo borrar las versiones individuales para ahorrar memoriarm(k20, k21, k22, k23)
En la edición 2020, nos referíamos a la identidad de género de una manera diferente a la que lo hicimos en la edición del 2021, así que la siguiente parte consiste en consolidar los datos de todas las ediciones.
Ver código
# Verificar las distintas formas de referirse al génerounique(div_rh$identidad_genero)
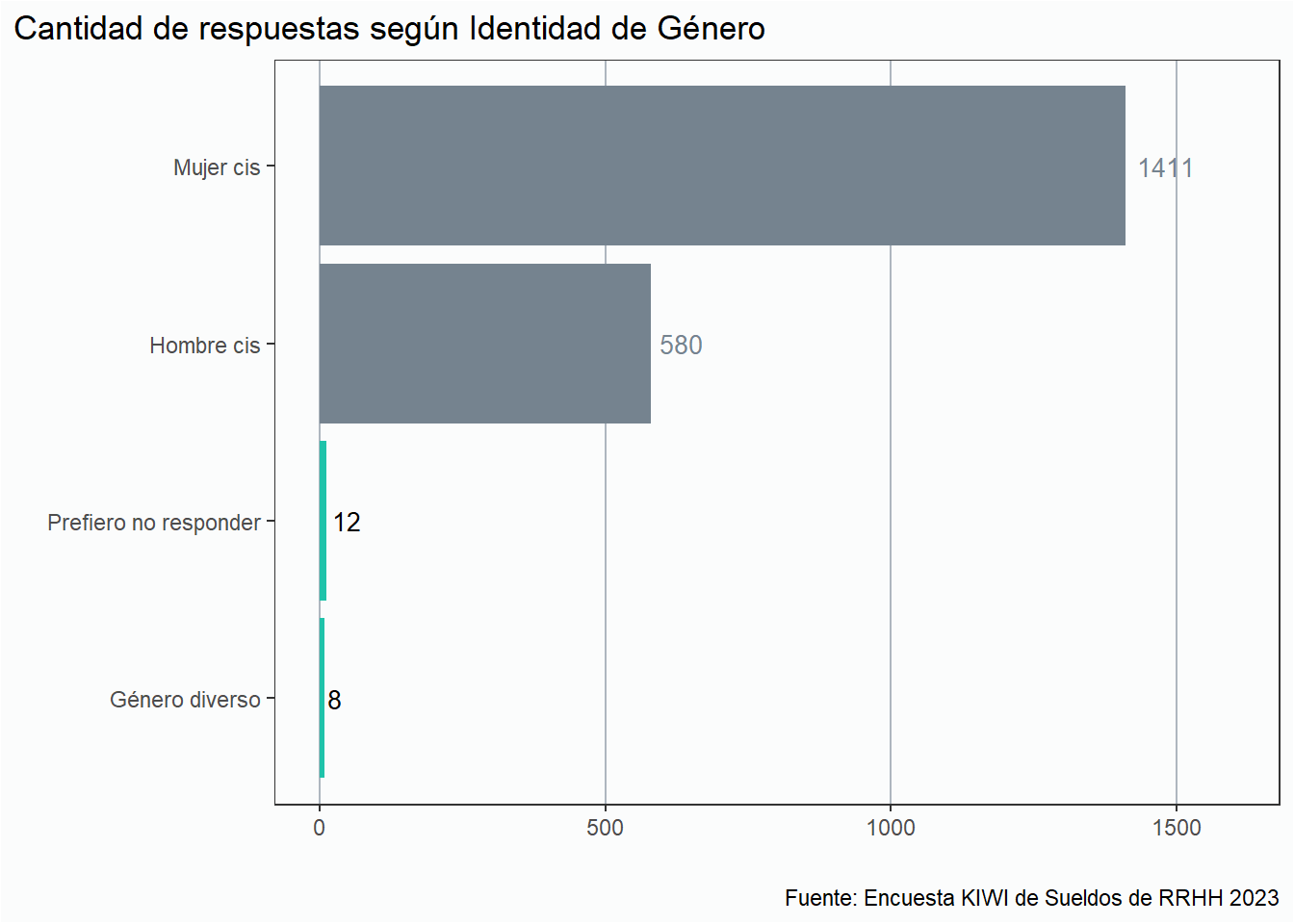
En los datos encontramos 6 formas diferentes de referirse a los hombres cis, y 5 formas diferentes de referirse a las mujeres cis, así que el siguiente paso es unificar estos valores para simplificar el análisis y la interpretación de los resultados.
El sufijo cis hace referencia a las personas que se identifican con el mismo género asignado al nacer.
Ver código
div_rh <- div_rh %>%mutate(identidad_genero =fct_collapse(identidad_genero,"Hombre cis"=c("Masculino","Hombre cis","Hombre","Hombre hetero. Que es cis?","Hombre heterosexual","Varon"),"Mujer cis"=c("Femenino","Mujer cis","mujer","Mujer heterosexual","Mujer"),"Género diverso"=c("Género diverso (género diverso / género fluido /otras minorías)","Mujer trans","No binario","Gay")))# Ver resultados del proceso anteriorunique(div_rh$identidad_genero)
[1] Hombre cis Mujer cis Prefiero no responder
[4] Género diverso
Levels: Mujer cis Género diverso Hombre cis Prefiero no responder
Ver código
div_rh <- div_rh %>%mutate(rubro =fct_collapse(rubro, "Agro"=c("Agricultura, plantaciones, otros sectores rurales", "Agricultura; plantaciones,otros sectores rurales"),"Alimentos"=c("Alimentación, bebidas", "Alimentación; bebidas; tabaco"),"Bancos y Finanzas"=c("Bancos, banca online", "Bancos; banca online;", "Servicios financieros seguros", "Servicios financieros; seguros"),"Autopartista"=c("Fabricación de material de transporte", "Terminales automotrices, fábricas autopartistas, y afines"), "Hotelería"="Hotelería, restauración, turismo","Metalurgia"=c("Industria metalúrgica, metalmecánica", "Producción de metales básicos"), "Medios"=c("Medios de comunicación, cultura, gráficos", "Medios de comunicación; cultura; gráficos"),"Minería"=c("Minería", "Minería (carbón, otra minería)"),"Oil & Gas"=c("Petróleo y producción de gas, refinación de petróleo", "Petróleo y producción de gas; refinación de petróleo"), "Consultoría"="Servicios de consultoría","Correos"=c("Servicios de correos y de telecomunicaciones", "Medios de comunicación; cultura; gráficos"),"Correos"=c("Servicios de correos y de telecomunicaciones", "Servicios de correos, y de telecomunicaciones"),"Servicios Públicos"=c("Servicios públicos (agua, gas, electricidad)", "Servicios públicos (agua;gas; electricidad)"),"Silvicultura"="Silvicultura; madera; celulosa; papel","Tecnología"=c("Tecnologías de información", "Tecnologías de Información, Sistemas, y afines"), "Textil"=c("Textiles, vestido, cuero, calzado", "Textiles; vestido; cuero; calzado"),"Transporte"=c("Transporte (incluyendo aviación civil, ferrocarriles por carretera)", "Transporte (incluyendo aviación civil; ferrocarriles por carretera)", "Transporte marítimo, puertos", "Transporte marítimo; puertos;" )))# Añadimos a los freelancers como servicios de consultoría dentro de la columna Rubrodiv_rh <- div_rh %>%mutate(rubro =if_else(trabajo =="Freelance", "Consultoría Freelance", as.character(rubro)))# Limpieza Puesto# Descartamos posiciones no relacionadas con RRHHdiv_rh <- div_rh %>%filter(!puesto %in%c("Juzgado Civil y Comercial", "Líder Ágil","Cuidado", "Asesor", "Jefe de Proyecto","-", "Inspección de calidad", "Jefe de Proyecto","Representante", "Técnico", "Asesoramiento", "-")) %>%mutate(puesto =str_trim(puesto, side ="both")) # Elimina espacios vacíos antes y después de cada palabra# Reemplazar los valores NA por Consultor Freelancediv_rh <- div_rh %>%mutate(puesto =if_else(is.na(puesto), "Consultor Freelance", puesto))# Unificación de Puestosdiv_rh <- div_rh %>%mutate(puesto =fct_collapse(puesto, "Gerente"=c("Gerente","Superintendente", "Director","Director ( escalafón municipal)"),"HRBP"=c("HRBP","Senior Consultoría", "specialist","especialista","Specialist","Especialista de selección por un lado (única persona en estas tareas) y HRBP de 2 equipos por otro","Especialista en selección IT", "Recruiter"),"Responsable"=c("Responsable","Coordinación","coordinación","Coordinador para 3 países","Coordinador de Payroll","Encargado","Coordinadora","Supervisor","Líder Ágil","Líder de selección","Team Leader"),"Administrativo"=c("Administrativo","Asistente","Asistente RRHH","Aux", "Auxiliar","consultor jr","El cargo es Asistente de CH, pero leo adelante Comunicación Interna, RSE, Capacitacion","Payroll Assistant"),"Analista"=c("Analista", "Analista semi senior","Asesoramiento", "Consultor", "Capacitador", "Consultor Ejecutivo","consultor jr","Desarrollador","Generalista","Profesional RRHH","Programador","Reclutador","Recruiter","Recruiter IT","Reclutadora", "Selectora","Senior","Senior Recruiter","Senior Consultoría","Sourcer (Recruiter)","Sourcer Specialist","talent","Talent Acquisition","IT RECRUITER","Auditor","Tech Recruiter","Analista de People Operations","Specialist")))
Cuanta diversidad de identidades de género y orientaciones sexuales hay en RRHH
En este punto creo que es importante aclarar que entre una edición y otra de la Encuesta KIWI hicimos cambios en el diseño del formulario, y por ejemplo, las preguntas sobre orientación sexual sólo se las hicimos a las personas que trabajan en relación de dependencia, con lo cual no tenemos una continuidad en los datos sobre el total de las personas que participaron, especialmente de quienes trabajan de manera freelance.
En primer lugar, veamos cuántas personas trabajan en RRHH según su identidad de género:
Ver código
gt(div_rh %>%group_by(edicion, identidad_genero) %>%count(sort =TRUE) %>%ungroup() %>%pivot_wider(names_from = edicion, values_from = n) %>%mutate(`2020`=coalesce(`2020`, 0),`2021`=coalesce(`2021`, 0),`2022`=coalesce(`2022`, 0),`2023`=coalesce(`2023`, 0),Total =`2020`+`2021`+`2022`+`2023`,Porcentaje =round(Total/sum(Total),3))) %>%fmt_percent(columns = Porcentaje,decimals =1) %>%tab_header(title ="Identidad de Género por Edición") %>%tab_source_note(source_note = fuente) %>%cols_label(identidad_genero ="Identidad de Género")
Identidad de Género por Edición
Identidad de Género
2020
2021
2022
2023
Total
Porcentaje
Mujer cis
518
403
261
229
1411
70.2%
Hombre cis
233
171
100
76
580
28.8%
Prefiero no responder
2
6
0
4
12
0.6%
Género diverso
4
2
2
0
8
0.4%
Fuente: Encuesta KIWI de Sueldos de RRHH 2023
Según la muestra que obtuvimos, menos del 1% de las personas que trabajan en RRHH son personas no binarias. Como para quede más claro veamóslo con un gráfico.
Ver código
div_rh %>%group_by(identidad_genero) %>%count(sort =TRUE) %>%ungroup() %>%ggplot(aes(y =reorder(identidad_genero, n), x = n, fill = identidad_genero)) +geom_col() + estilov +geom_text(aes(label = n, hjust =-0.2),size =3.5,color =c(gris, gris, "black", "black"))+scale_fill_manual(values =c(gris, verde, gris, verde, gris)) +scale_x_continuous(limits =c(0, 1600)) +labs(title ="Cantidad de respuestas según Identidad de Género",x ="", y ="",caption = fuente) +theme(legend.position ="none")
Por decirlo amablemente: Hay muchas oportunidades de mejora acá.
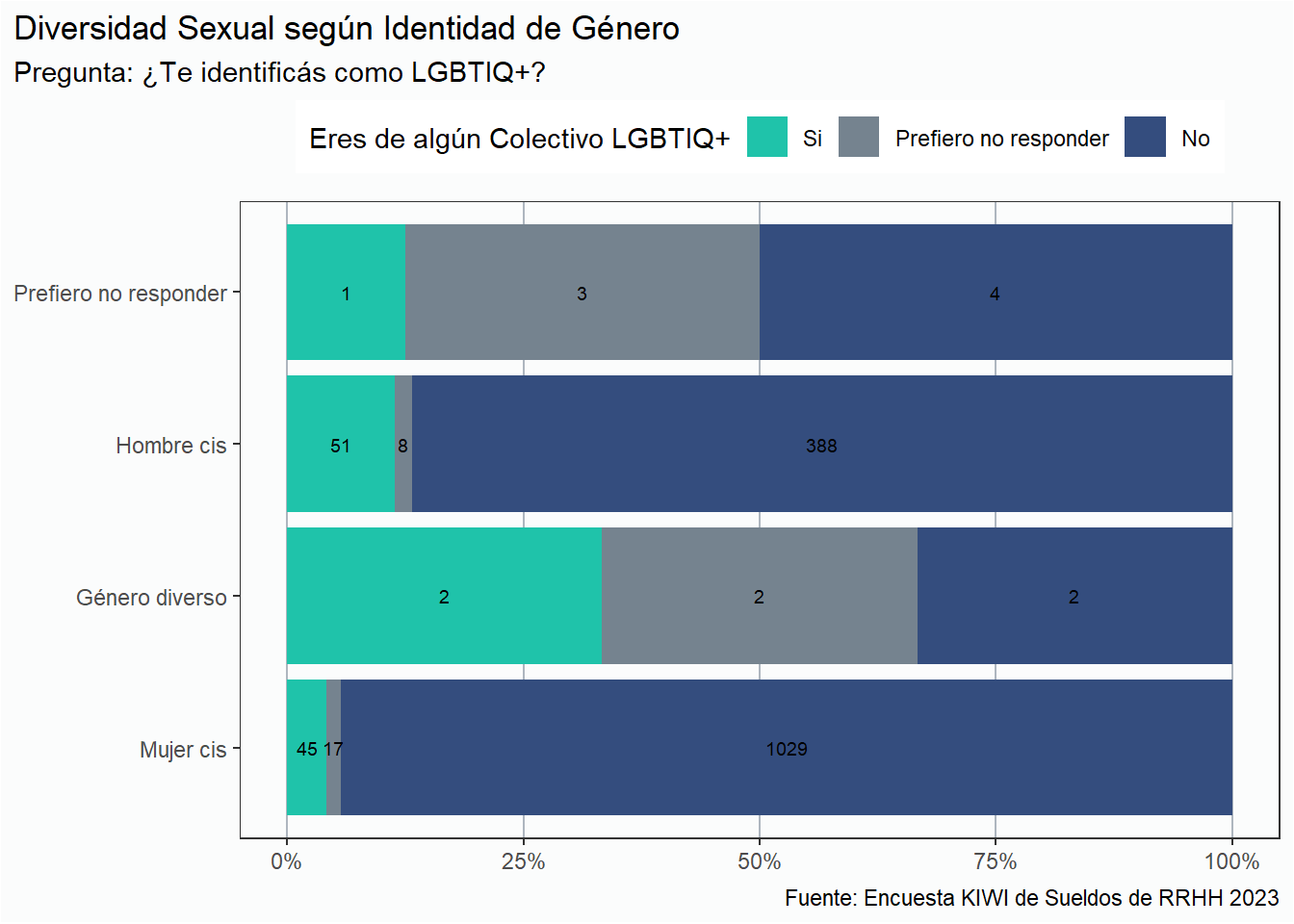
Y ahora veamos la cantidad de respuestas según la orientación sexual de las personas que participaron de la encuesta. Dado que en la edición 2021 esta era una sección voluntaria, la cantidad de respuestas va a ser distinta que en la tabla anterior. Además, fue algo que no le preguntamos a las personas que trabajan de manera independiente.
La pregunta que hicimos fue ¿Te identificás como LGBTIQ+ (lesbiana, gay, bisexual, transexual, otra minoría sexual)?. He aquí las respuestas:
Al menos respecto de esta pregunta, tenemos una mayor representación de diversidades sexuales. Nuevamente, esta muestra no es representativa de todas las personas que trabajan en RRHH, pero esperamos que permita discutir el tema.
Ver código
div_rh %>%filter(!is.na(diversidad_sexual)) %>%group_by(identidad_genero, diversidad_sexual) %>%tally() %>%ungroup() %>%ggplot(aes(y = identidad_genero, x = n, fill = diversidad_sexual )) +geom_col(position ="fill") +geom_text(aes(label = n), position =position_fill(vjust =0.5), size =2.5) + estilov +theme(legend.position ="top") +guides(fill =guide_legend(reverse = T)) +scale_x_continuous(labels = scales::percent_format(accuracy =1))+labs(title ="Diversidad Sexual según Identidad de Género",subtitle ="Pregunta: ¿Te identificás como LGBTIQ+?", fill ="Eres de algún Colectivo LGBTIQ+",x =NULL, y =NULL, caption = fuente) +scale_fill_manual(values =c(azul, gris, verde))
El tamaño de las barras reflejan la proporción de cada respuesta según la identidad de género de cada participante. Por ejemplo, en el caso de las personas que se identifican como Hombres cis, 51 personas se identifican como parte de la comunidad LGBTIQ+ (un 11.4%). 45 Mujeres cis (4.1%) pertenecen a este colectivo.
En qué rubros se da la mayor tasa de diversidad
Ahora analicemos los rubros. Dado que no tenemos muchas personas con diversas identidades de género, listaremos todos los rubros.
Entre los primeros rubros (fuera de Otros) nos encontramos con actividades relacionadas con servicios. Recién en el 5° puesto nos encontramos con el primer rubro relacionado con trabajo de mano de obra intensivo (Construcción).
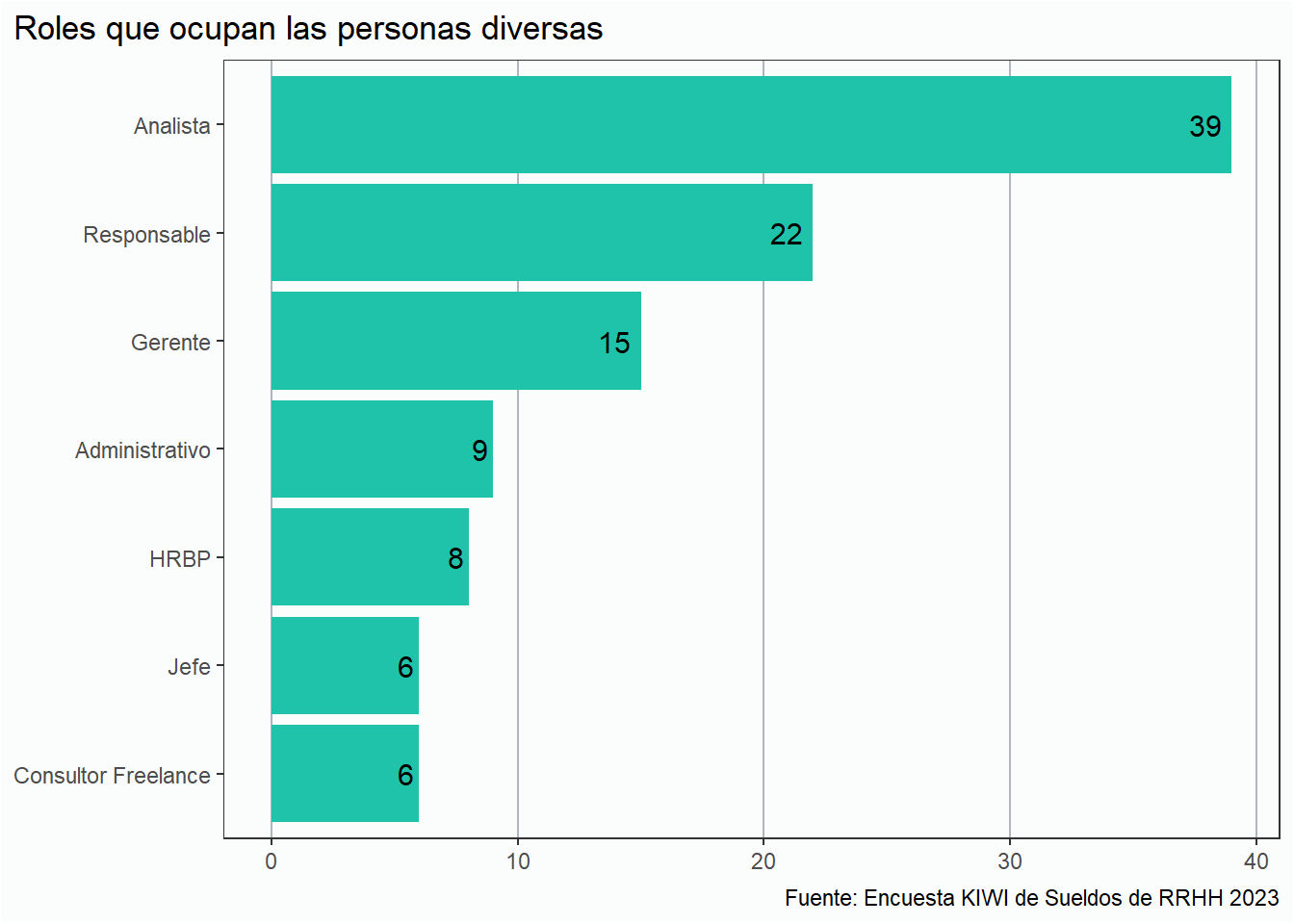
Qué roles ejercen las personas diversas
Por último, veamos en qué roles se desempeñan las personas que pertenecen a algún colectivo de diversidad dentro de RRHH.
Ver código
# Crear un flag para posiciones de manager (Gerente, Jefe o Responsable)div_rh <- div_rh %>%mutate(manager =if_else(puesto %in%c("Gerente", "Jefe", "Responsable"),1, 0))# Si el valor de la columna identidad_genero es igual a Género diverso o el valor de la columna diversidad_sexual es igual a Si, entonces el valor en la nueva columna llamada diversa es 1, de lo contrario poner 0.div_rh <- div_rh %>%mutate(diversa =if_else(identidad_genero =="Género diverso"| diversidad_sexual =="Si",1, 0))managers_porcentaje <- div_rh %>%filter(diversa ==1) %>%group_by(manager) %>%count() %>%ungroup() %>%mutate(porcentaje = n/sum(n))puestos_porcentaje <- div_rh %>%filter(diversa ==1) %>%group_by(puesto) %>%count(sort = T) %>%ungroup() %>%mutate(porcentaje = n/sum(n))# Visualizaciónggplot(puestos_porcentaje, aes(x = n, y =reorder(puesto, n))) +geom_col(fill = verde) +geom_text(aes(label = n), hjust =1.3,size =4) + estilov +labs(title ="Roles que ocupan las personas diversas",x =NULL, y =NULL,caption = fuente)
Algo interesante de este gráfico es que un 41% ocupan algún puesto jerárquico (definidos como Gerente, Jefe, o Responsable) lo cual nos parece algo positivo.
Sólo 6 personas, un 6%, trabajan por su cuenta como Consultor Freelance, el cual es un dato alentador mirándolo desde el punto de vista de la formalidad laboral y la estabilidad.
Estos son datos que están sesgados por la muestra de datos, pero la hipótesis inicial que teníamos era que el porcentaje de freelancers sería mayor en este caso.
Acoso en el trabajo
Ahora comparemos las respuestas a la pregunta ¿Sufriste alguna situación de acoso, abuso o de discriminación en algún trabajo?. Primero, analicemos los resultados según si la persona pertenece a algún colectivo de diversidad o no.
Ver código
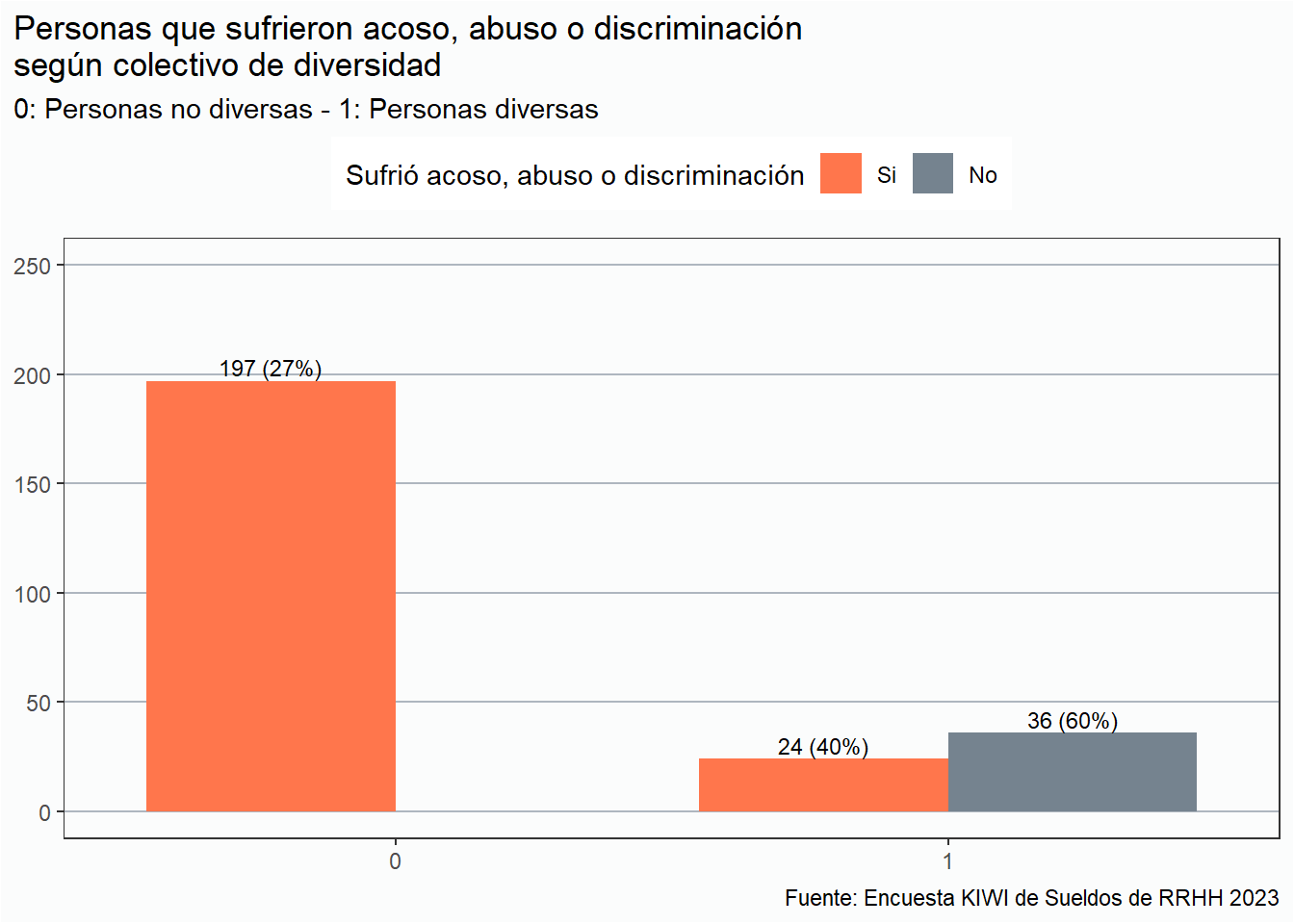
div_rh %>%mutate(sufrio_acoso =fct_collapse(sufrio_acoso,"Si"=c("Si", "agresión verbal.", "Mobbing","no en el actual", "Alguna vez sufrí maltrato psicológico","Lo máximo fue \"sos lesbiana porque no te maquillas\"","Sí claro, abuso de autoridad","Sí. Son sutiles pero están.","no en el actual" ,"No. Pero si muchos comentarios marchistas durante mi carrera. No ahora.","en un trabajo anterior, acoso psicológico y misoginia","no, pero he sido testigo"))) %>%filter(sufrio_acoso %in%c("Si", "No"), !is.na(diversa)) %>%group_by(diversa, sufrio_acoso) %>%summarise(cantidad =n()) %>%mutate(porcentaje = cantidad/sum(cantidad)) %>%ggplot(aes(x =factor(diversa), y = cantidad, fill = sufrio_acoso)) +geom_col(position ="dodge") +geom_text(aes(label =paste0(cantidad, " (", scales::percent(porcentaje, accuracy =1), ")")),position =position_dodge(0.9), vjust =-0.3, size =3) + estiloh +labs(title ="Personas que sufrieron acoso, abuso o discriminación\nsegún colectivo de diversidad", subtitle ="0: Personas no diversas - 1: Personas diversas",x =NULL, y =NULL, caption = fuente,fill ="Sufrió acoso, abuso o discriminación") +theme(legend.position ="top") +scale_fill_manual(values =c(naranja, gris)) +scale_y_continuous(limits =c(0,250))
El 40% de las personas diversas, ya sea por su identidad de género o por su orientación sexual sufrieron alguna situación de acoso, abuso, o discriminación, frente a un 28% de las personas cis y heterosexuales.
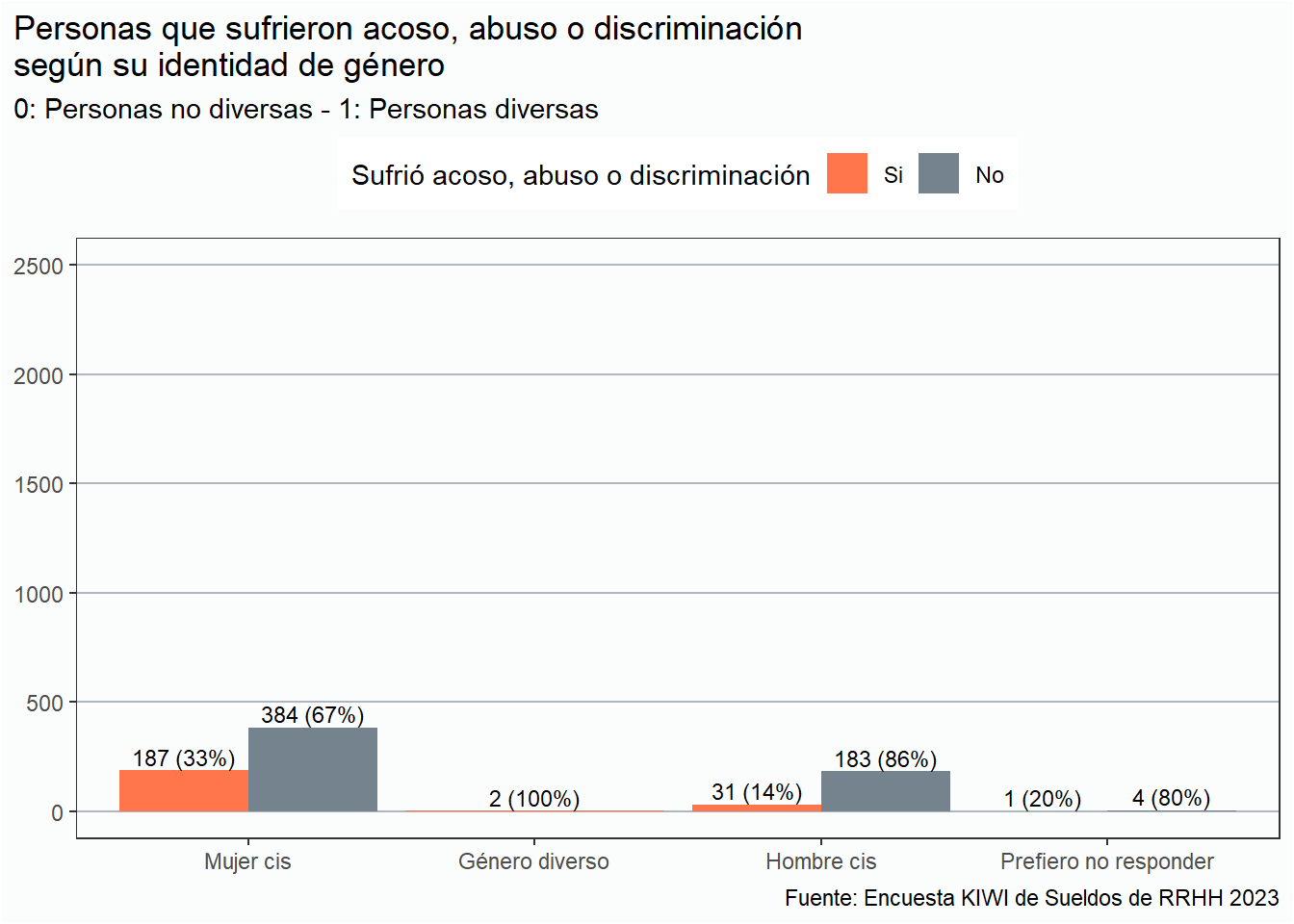
Ahora desagreguemos el gráfico anterior según la identidad de género de las personas:
Ver código
div_rh %>%mutate(sufrio_acoso =fct_collapse(sufrio_acoso,"Si"=c("Si", "agresión verbal.", "Mobbing","no en el actual", "Alguna vez sufrí maltrato psicológico","Lo máximo fue \"sos lesbiana porque no te maquillas\"","Sí claro, abuso de autoridad","Sí. Son sutiles pero están.","no en el actual" ,"No. Pero si muchos comentarios marchistas durante mi carrera. No ahora.","en un trabajo anterior, acoso psicológico y misoginia","no, pero he sido testigo"))) %>%filter(sufrio_acoso %in%c("Si", "No")) %>%group_by(identidad_genero, sufrio_acoso) %>%summarise(cantidad =n()) %>%mutate(porcentaje = cantidad/sum(cantidad)) %>%ggplot(aes(x = identidad_genero, y = cantidad, fill = sufrio_acoso)) +geom_col(position ="dodge") +geom_text(aes(label =paste0(cantidad, " (", scales::percent(porcentaje, accuracy =1), ")")),position =position_dodge(0.9), vjust =-0.3, size =3) + estiloh +labs(title ="Personas que sufrieron acoso, abuso o discriminación\nsegún su identidad de género", subtitle ="0: Personas no diversas - 1: Personas diversas",x =NULL, y =NULL, caption = fuente,fill ="Sufrió acoso, abuso o discriminación") +theme(legend.position ="top") +scale_fill_manual(values =c(naranja, gris)) +scale_y_continuous(limits =c(0,2500))
En este último gráfico podemos apreciar las distintas realidades de las personas. Un tercio de las mujeres cissufrió al menos una vez alguna situación de acoso, abuso o discriminación versus un 15% de los hombres cis. Más allá de la cantidad de respuestas recibidas, las tendencias son claras.
Machismo
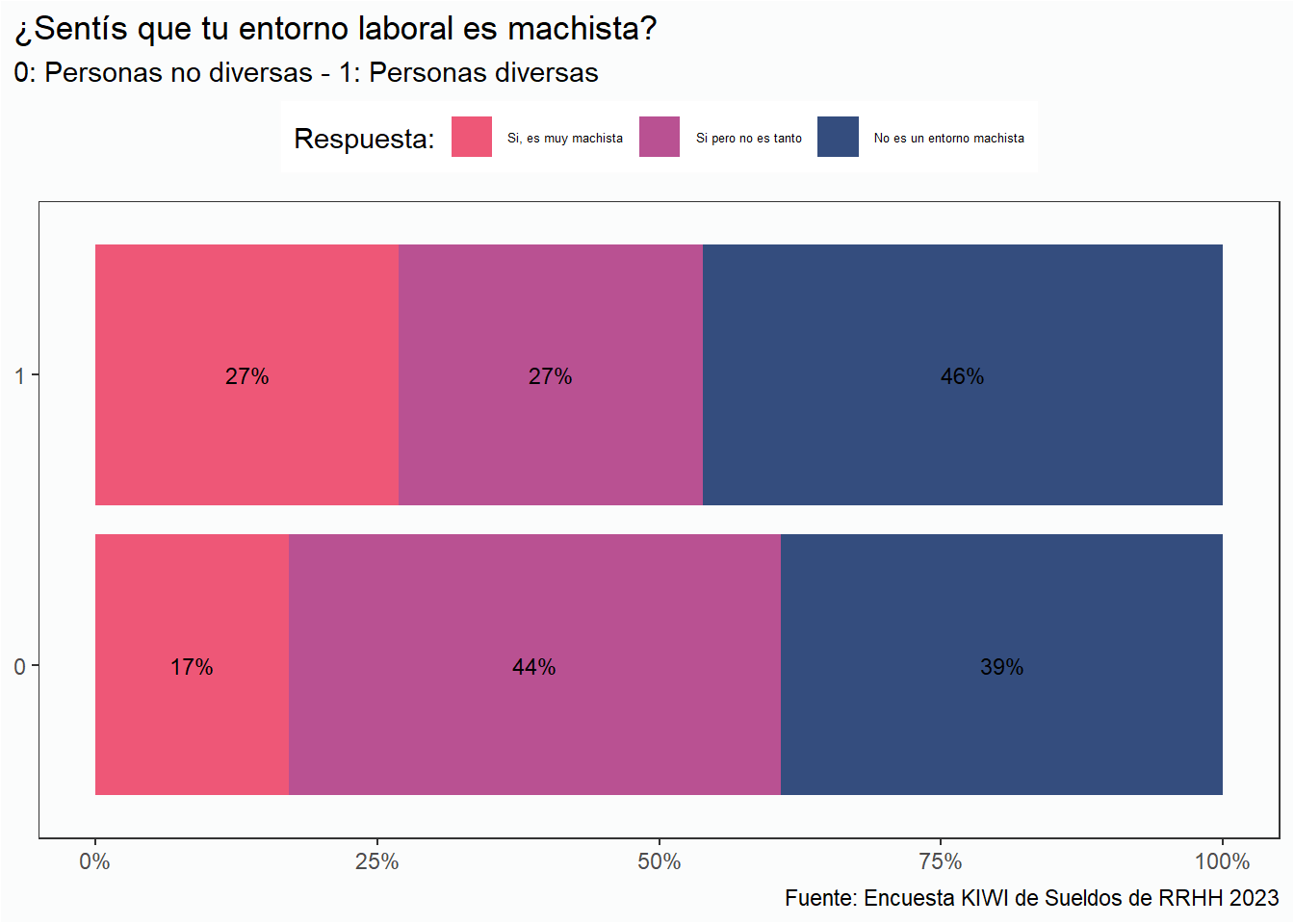
La siguiente pregunta, ¿Sentís que tu entorno laboral es machista?, la realizamos por primera vez en 2022, así que en primer lugar comparemos los resultados en función de si las personas son diversas o no.
Ver código
# Creamos un dataframe específico para este análisis.machismo <- div_rh %>%filter(!is.na(diversa), machismo %in%c("No es un entorno machista","Si pero no es tanto","Si, es muy machista")) %>%mutate(machismo =factor(machismo, levels =c("No es un entorno machista","Si pero no es tanto","Si, es muy machista")))machismo_score <- machismo %>%mutate(diversa =factor(diversa)) %>%group_by(diversa, machismo) %>%summarise(respuestas =n()) %>%mutate(porcentaje = respuestas/sum(respuestas)) ggplot(machismo_score, aes(y = diversa, x = respuestas, fill = machismo)) +geom_col(position ="fill") +scale_fill_manual(values =c(azul, rosa1, rosa2)) +geom_text(aes(label = scales::percent(porcentaje, accuracy =1)), position =position_fill(vjust =0.5), size =3) + estilo +scale_x_continuous(labels = scales::percent_format(accuracy =1)) +theme(legend.position ="top",legend.text =element_text(size =5),legend.background =element_rect(colour ="#FCFCFC")) +guides(fill =guide_legend(reverse =TRUE)) +labs(title ="¿Sentís que tu entorno laboral es machista?",subtitle ="0: Personas no diversas - 1: Personas diversas",x =NULL, y =NULL, caption = fuente,fill ="Respuesta:")
Entre las personas diversas encontramos respuestas con mayor cantidad de respuestas en los extremos, 46% no sienten que su entorno sea machista, y un 27% sienten que es muy machista.
Entre las personas heteronormativas un 44% que su entorno no es tan machista.
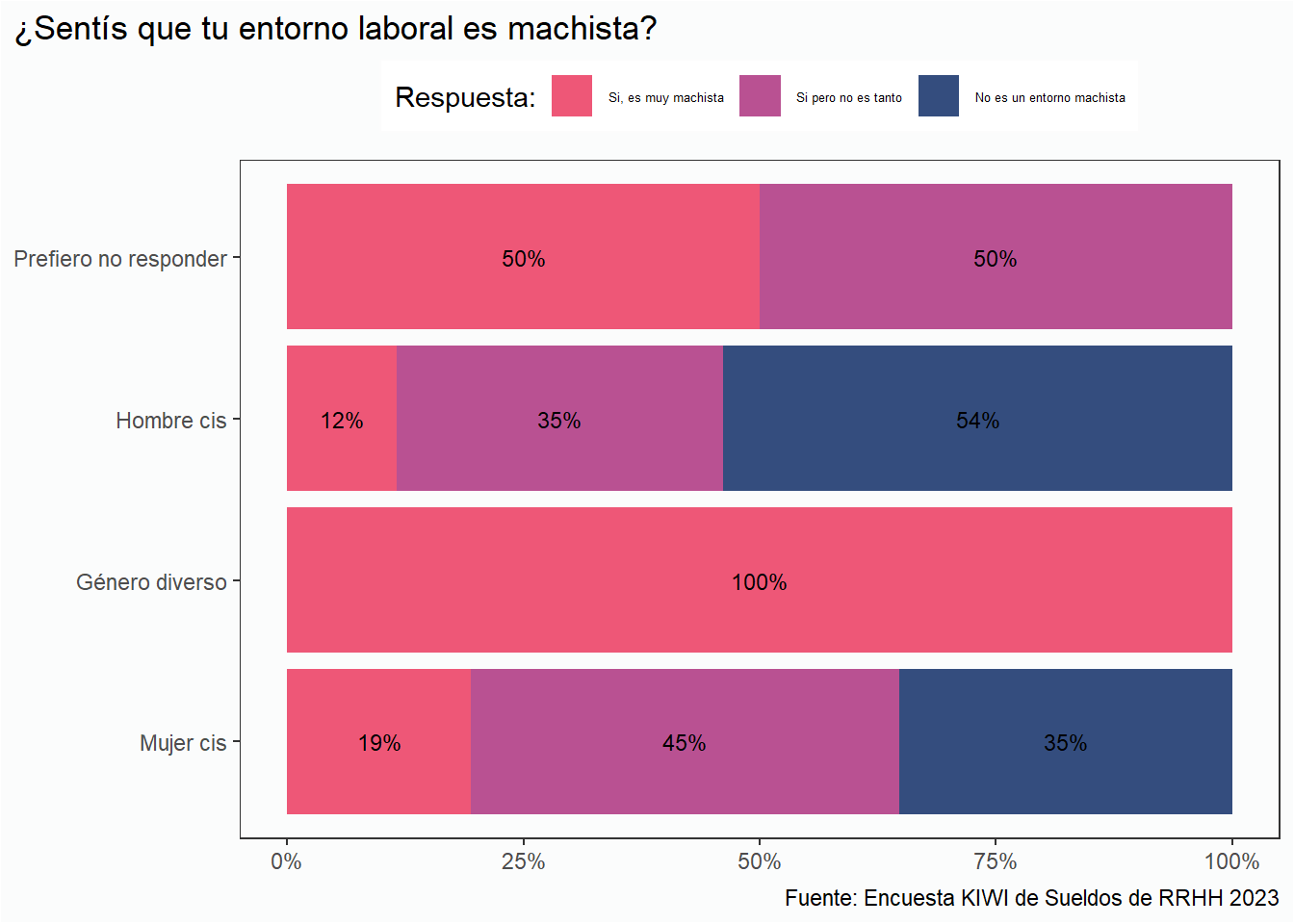
Analizando las respuestas según la identidad de género, no sorprende que las mujeres tengan una percepción mayor que los hombres sobre si el entorno laboral es machista.
Ver código
machismo_genero <- machismo %>%filter(identidad_genero !="Mujer trans") %>%group_by(identidad_genero, machismo) %>%summarise(respuestas =n()) %>%mutate(porcentaje = respuestas/sum(respuestas)) ggplot(machismo_genero, aes(y = identidad_genero, x = respuestas, fill = machismo)) +geom_col(position ="fill") +scale_fill_manual(values =c(azul, rosa1, rosa2)) +geom_text(aes(label = scales::percent(porcentaje, accuracy =1)), position =position_fill(vjust =0.5), size =3) + estilo +scale_x_continuous(labels = scales::percent_format(accuracy =1)) +theme(legend.position ="top",legend.text =element_text(size =5),legend.background =element_rect(colour ="#FCFCFC")) +guides(fill =guide_legend(reverse =TRUE)) +labs(title ="¿Sentís que tu entorno laboral es machista?",x =NULL, y =NULL, caption = fuente,fill ="Respuesta:")
Veamos cuántas personas con alguna discapacidad participaron de la edición actual:
Ver código
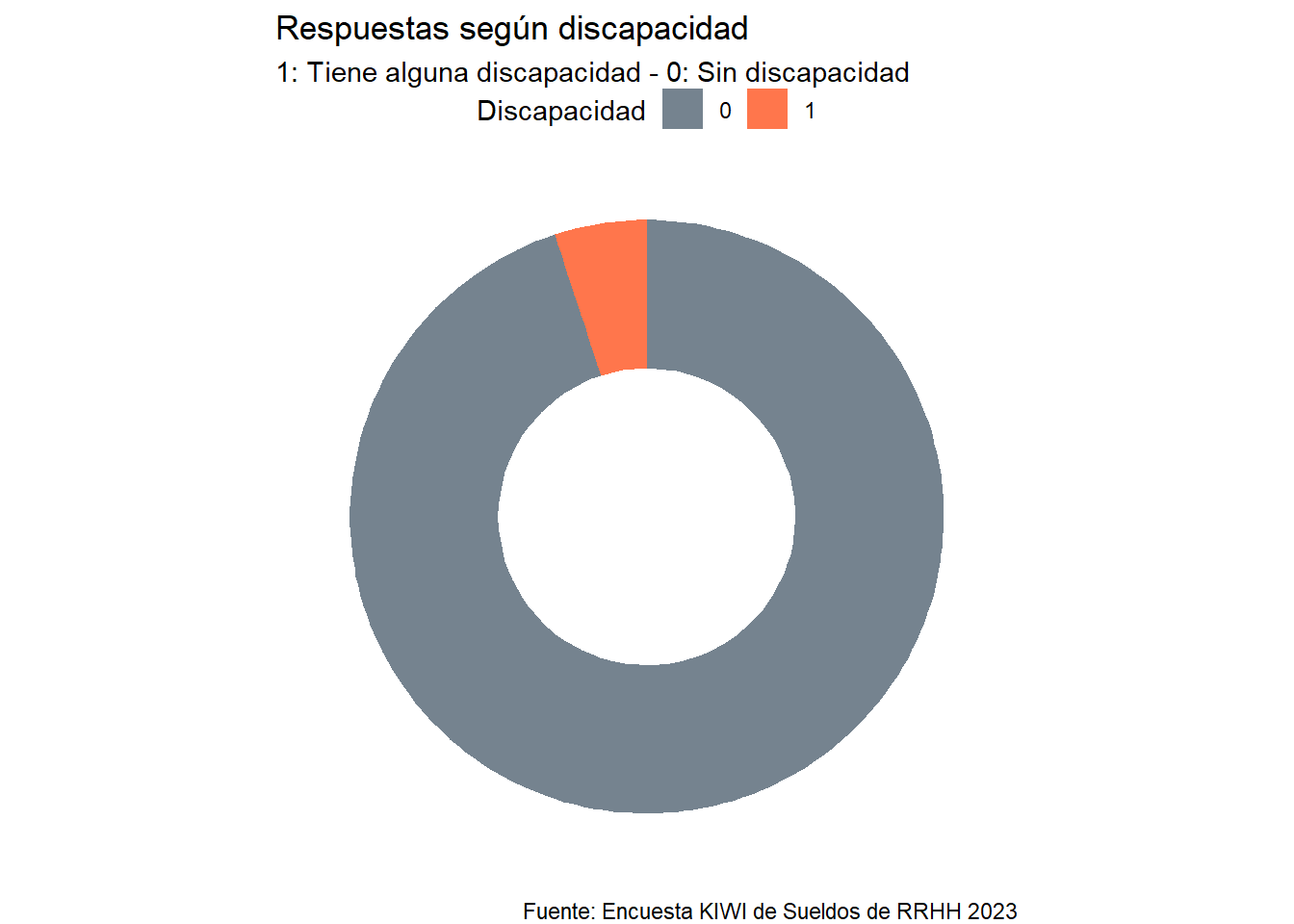
kiwi <- kiwi %>%mutate(discapacidad =fct_collapse(discapacidad,"Sin discapacidad"=c("No tengo ninguna discapacidad","NO", "No")),tiene_discapacidad =factor(if_else(discapacidad =="Sin discapacidad", 0, 1)))div <- kiwi %>%filter(!is.na(discapacidad)) %>%select(tiene_discapacidad) %>%group_by(tiene_discapacidad) %>%summarise (n =n()) %>%mutate(freq = n/sum(n)) %>%arrange(-n)# Compute the cumulative percentages (top of each rectangle)div$ymax <-cumsum(div$freq)# Compute the bottom of each rectanglediv$ymin <-c(0, head(div$ymax, n=-1))# Compute label positiondiv$labelPosition <- (div$ymax + div$ymin) /2# Compute a good labeldiv$label <-paste0(div$genero, "\n Cant: ", div$n)# Make the plotggplot(div, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=tiene_discapacidad)) +geom_rect() +coord_polar(theta="y") +# Try to remove that to understand how the chart is built initiallyxlim(c(2, 4)) +# Try to remove that to see how to make a pie chartscale_fill_manual(values =c(gris, naranja)) +theme_void() +theme(legend.position ="top",panel.background =element_blank(),plot.title.position ="plot",text =element_text(family ="Roboto")) +labs(title ="Respuestas según discapacidad",subtitle ="1: Tiene alguna discapacidad - 0: Sin discapacidad",fill ="Discapacidad", caption = fuente)
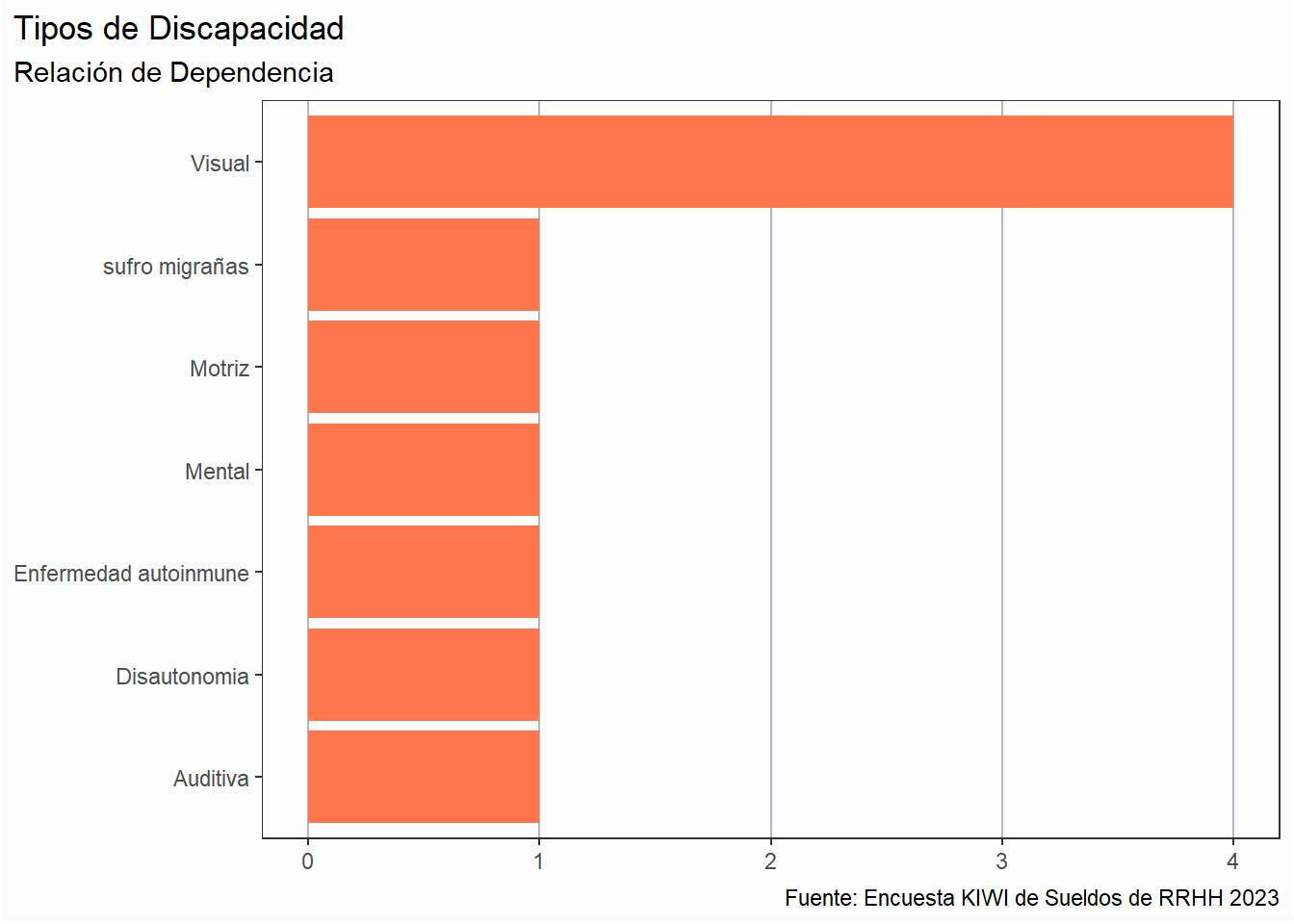
En la actual edición contamos sólo con un 5% de colegas con alguna discapacidad trabajando en RRHH, las cuales son las siguientes:
Ver código
kiwi %>%filter(!is.na(discapacidad), tiene_discapacidad ==1) %>%group_by(discapacidad) %>%summarise(cant =n()) %>%ungroup() %>%ggplot(aes(x = cant, y =reorder(discapacidad, cant))) +geom_col(fill = naranja) + estilov +labs(title ="Tipos de Discapacidad",subtitle ="Relación de Dependencia",x =NULL, y =NULL,caption = fuente)
Veamos cómo fue la evolución de esta respuesta a lo largo de las ediciones de esta encuesta.
Ver código
disc_rh %>%filter(tiene_discapacidad ==1) %>%group_by(edicion) %>%summarise(cant =n()) %>%ungroup() %>%ggplot(aes(x =factor(edicion), y = cant)) +geom_col(fill = naranja) +geom_text(aes(label = cant),vjust =1.2,size =3) + estiloh +labs(title ="Respuestas de Personas con Discapacidad",subtitle ="Relación de Dependencia",x =NULL, y =NULL,caption = fuente)
Puestos
Si bien la mayor cantidad de personas con discapacidad históricamente se desempeñan en roles de Analista, es interesante apreciar que en total tenemos prácticamente la misma cantidad (18) en roles de liderazgo (Gerente, Jefe o Resposable).
Esto nos parece positivo porque es una muestra no sólo de diversidad, sino también de inclusión. Consideramos que no sólo es importante contratar personas con discapacidad, sino también darles las oportunidades de desarrollo que le daríamos a cualquier persona de la compañía.
Ver código
gt(disc_rh %>%filter(!is.na(discapacidad),!is.na(puesto), tiene_discapacidad ==1) %>%group_by(edicion, puesto) %>%summarise(cant =n()) %>%ungroup() %>%pivot_wider(names_from = edicion,values_from = cant) %>%mutate(across(c(`2020`:`2023`),~coalesce(.x, 0)),Total =`2020`+`2021`+`2022`,`2023`) %>% janitor::adorn_totals()) %>%cols_label(puesto ="Puesto") %>%tab_header(title ="Puestos de Personas con Discapacidad") %>%tab_source_note(source_note = fuente)
Puestos de Personas con Discapacidad
Puesto
2020
2021
2022
2023
Total
Administrativo
3
0
0
3
3
Analista
9
8
31
3
48
Consultor Freelance
6
0
0
0
6
Responsable
4
3
6
2
13
Gerente
3
2
10
2
15
Jefe
2
2
6
0
10
HRBP
0
2
12
0
14
Pasante
0
0
1
0
1
Total
27
17
66
10
110
Fuente: Encuesta KIWI de Sueldos de RRHH 2023
Contratación de personas con discapacidad
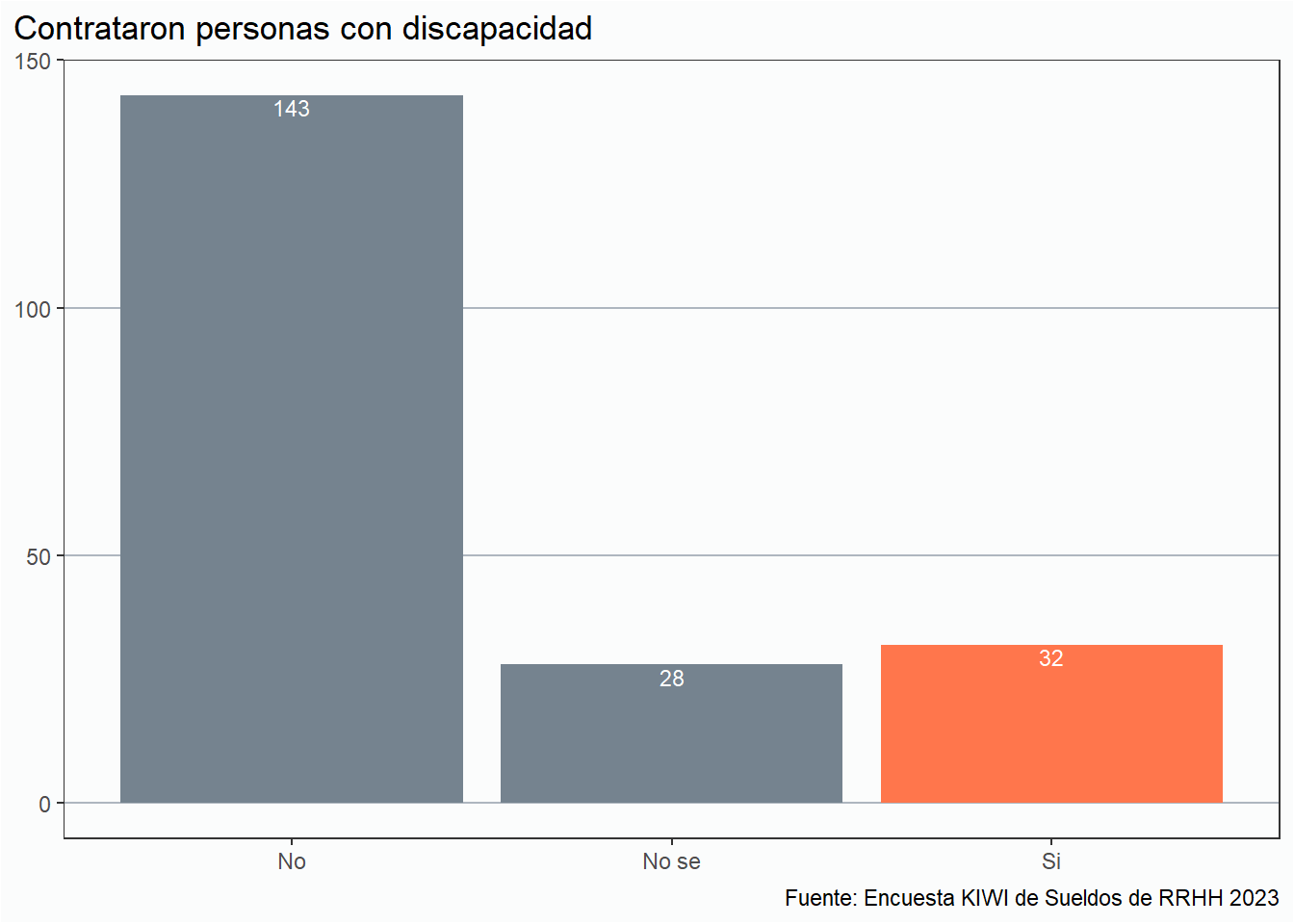
En esta edición incluimos la pregunta En lo que va del año, ¿han contratado en tu empresa a personas con discapacidad? para analizar si las empresas están activamente tomando acciones de inclusión.
Ver código
kiwi %>%filter(!is.na(contrata_discapacidad)) %>%group_by(contrata_discapacidad) %>%summarise(cant =n()) %>%ungroup() %>%ggplot(aes(x = contrata_discapacidad, y = cant, fill = contrata_discapacidad)) +geom_col() +geom_text(aes(label = cant),vjust =1.2, color ="white",size =3) +scale_fill_manual(values =c(gris, gris, naranja)) + estiloh +labs(title ="Contrataron personas con discapacidad",x =NULL, y =NULL,caption = fuente) +theme(legend.position ="none")
En esta edición, 32 (un 16%) afirmaron que en sus empresas han contratado personas con discapacidad en sus organizaciones. Esto nos lleva a la siguientes preguntas: estas compañías, ¿son nacionales o multinacionales?, ¿Qué tamaño tienen las empresas?
Freelancers
En este relevamiento participan colegas que trabajan en relación de dependencia y también de manera freelance. Este es el análisis desarrollado en base a las respuestas de las personas que trabajan de manera independiente o en sus propias empresas.
Respuestas por país
En el caso de las personas freelance, la mayoría de las respuestas obtenidas fueron de Argentina. Por eso reiteramos, que los resultados no son representativos de los países.
Cantidad de respuestas por país
Freelance
País
Cuenta
Argentina
26
México
1
Perú
1
Uruguay
1
Total
29
Fuente: Encuesta KIWI de Sueldos de RRHH 2023
Respuestas por Género
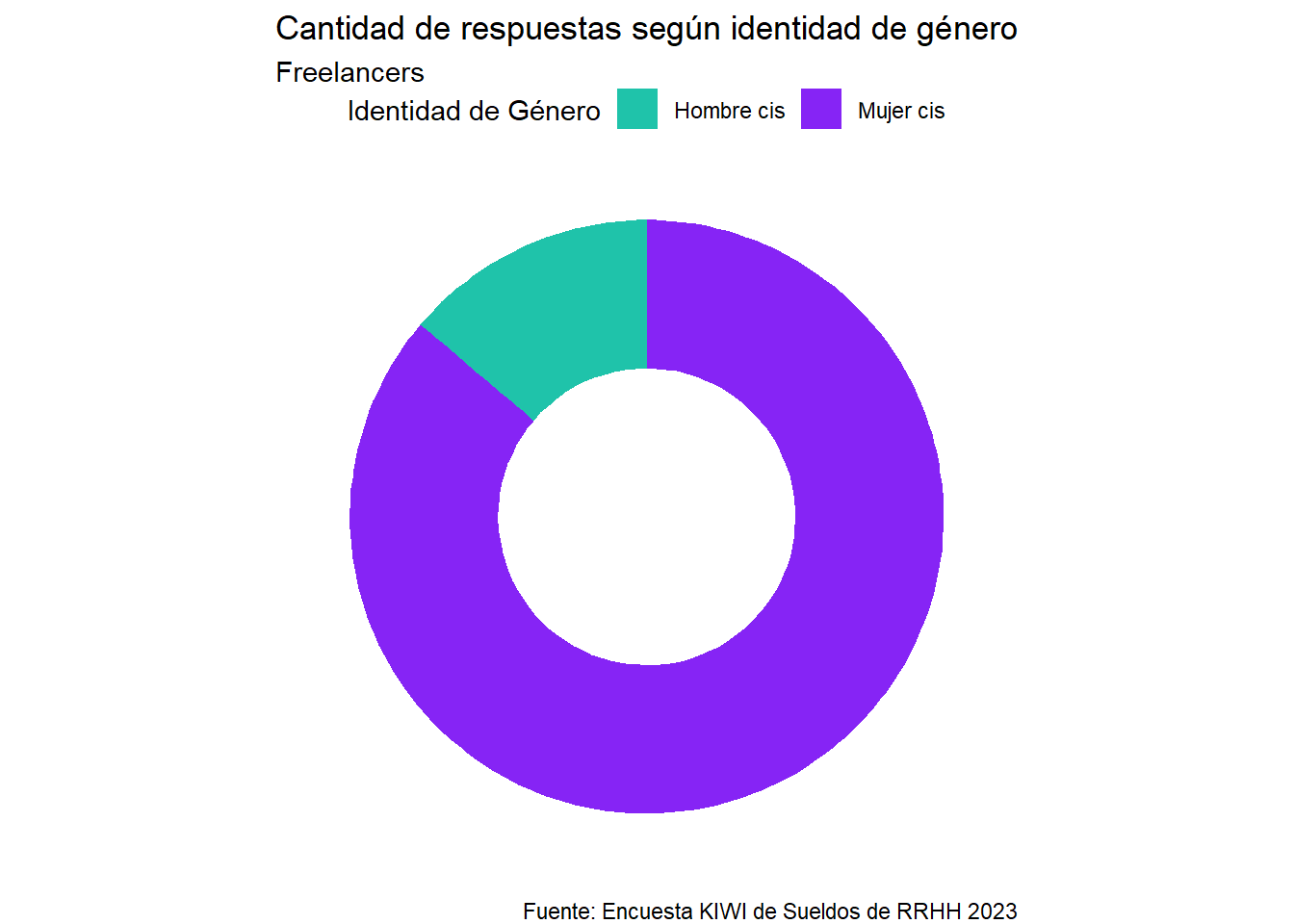
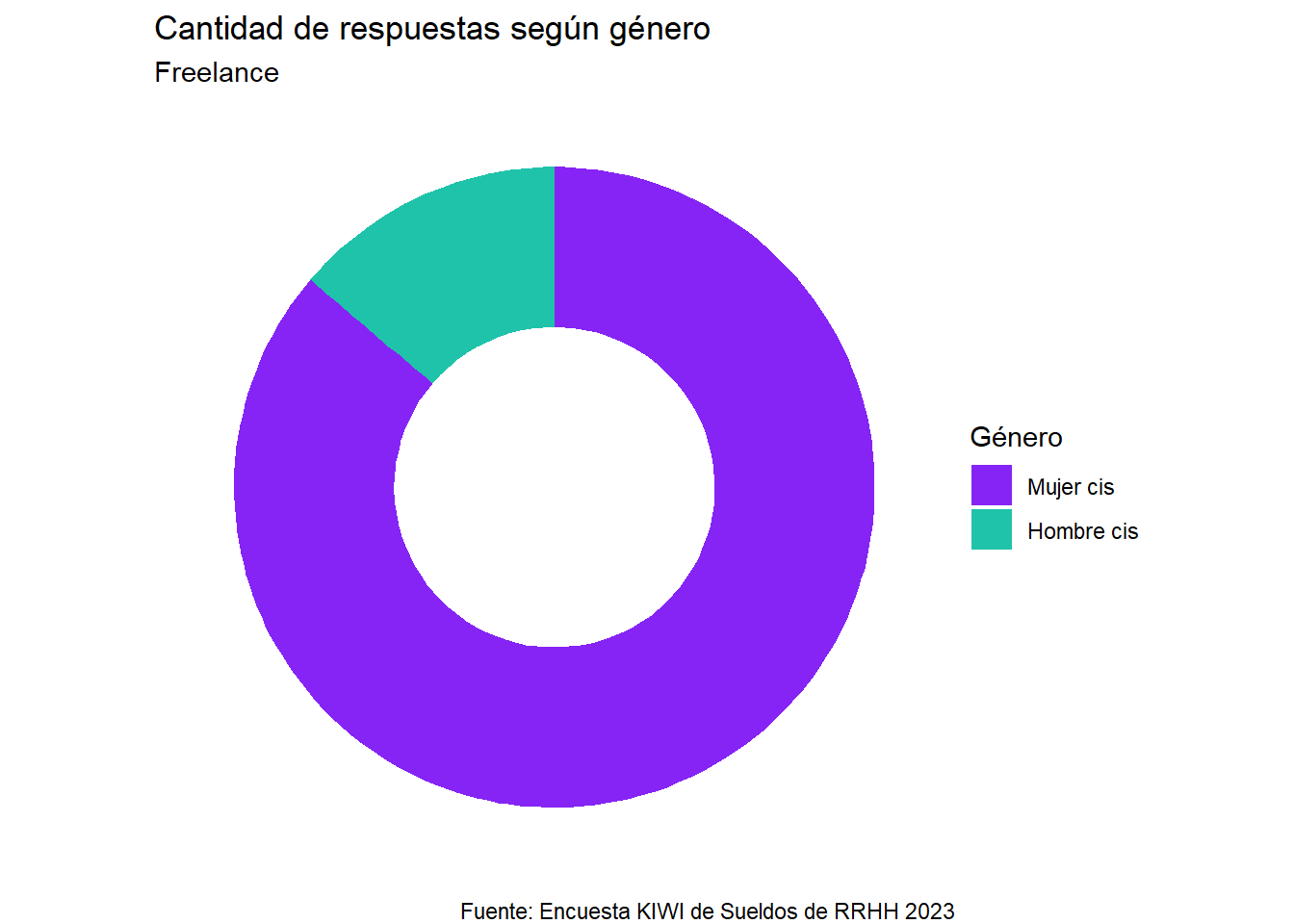
La participación según el género de las personas freelance, es la siguiente:
Podemos observar que la mayoría de las respuestas fueron de Mujeres cis, manteniendo la misma tendencia que las personas en relación de dependencia.
Género
Cuenta
Mujer cis
25
Hombre cis
4
Total
29
Respuestas por Educación
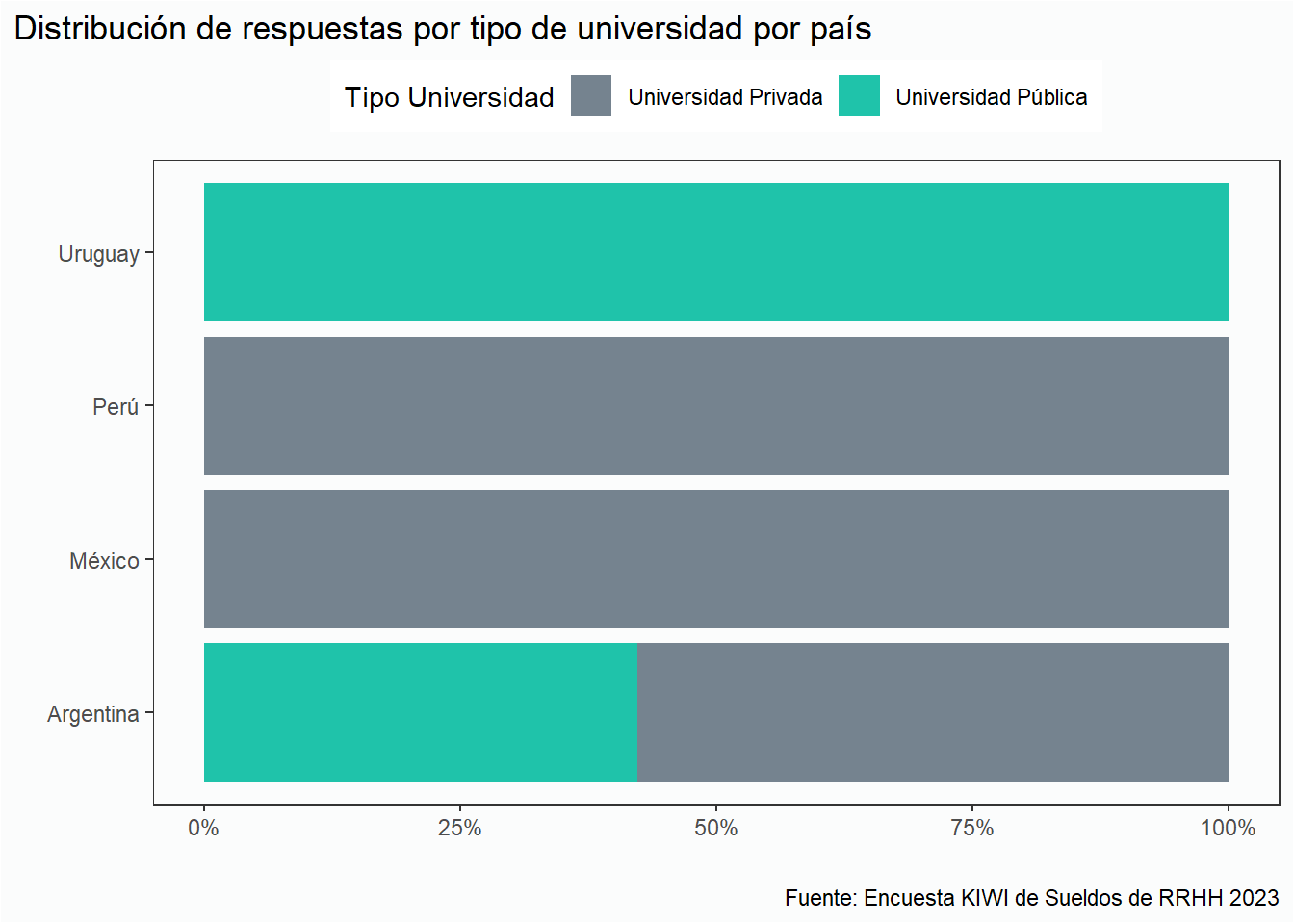
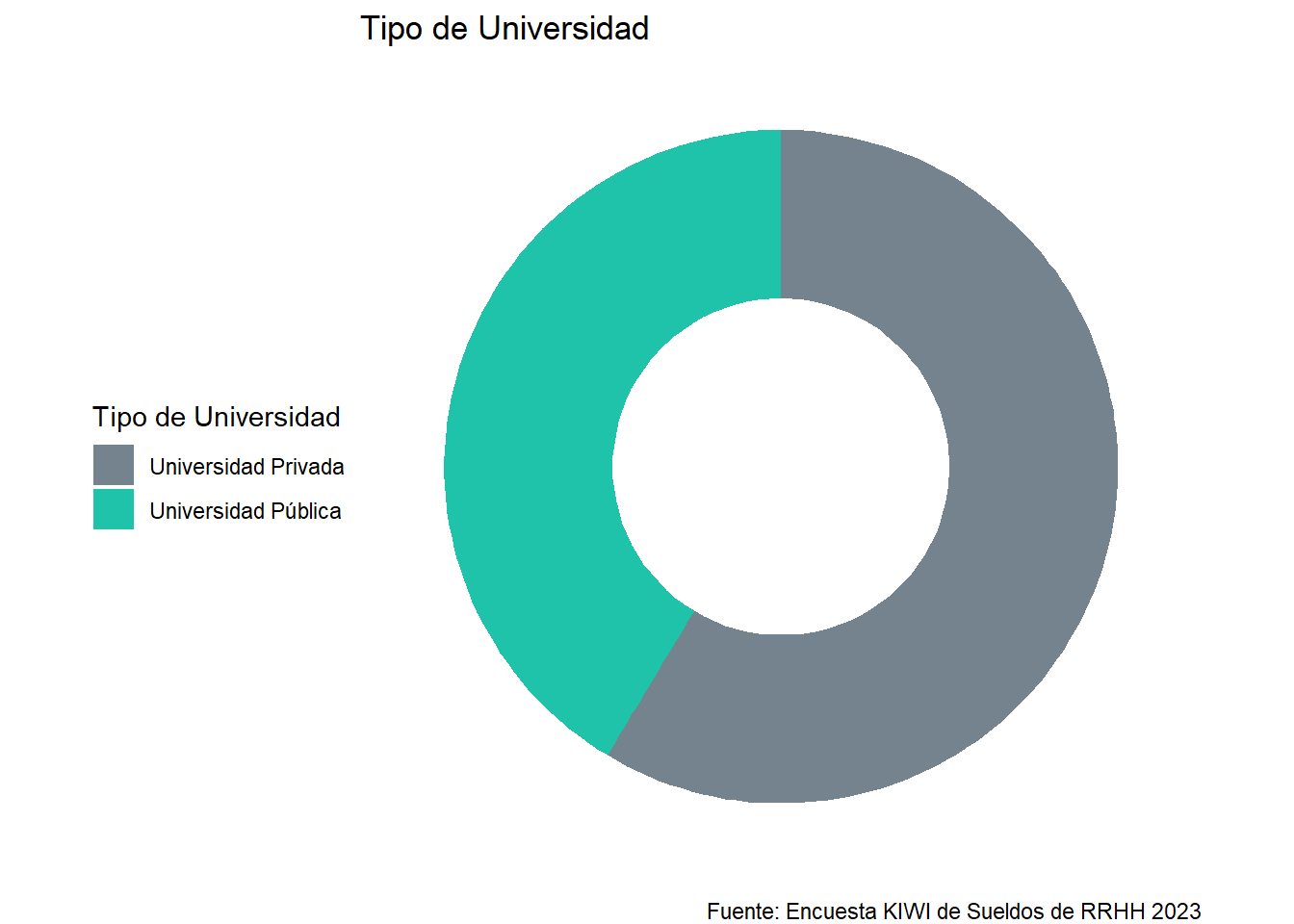
En esta sección queremos indagar si hay relación entre la formación y la exportacion de los servicios, y si impacta también el tipo de universidad, pública o privada, en dichas prestaciónes. Primero veamos como se distribuye la muestra entre profesionales provenientes de universidades públicas y privadas de los diferentes paises:
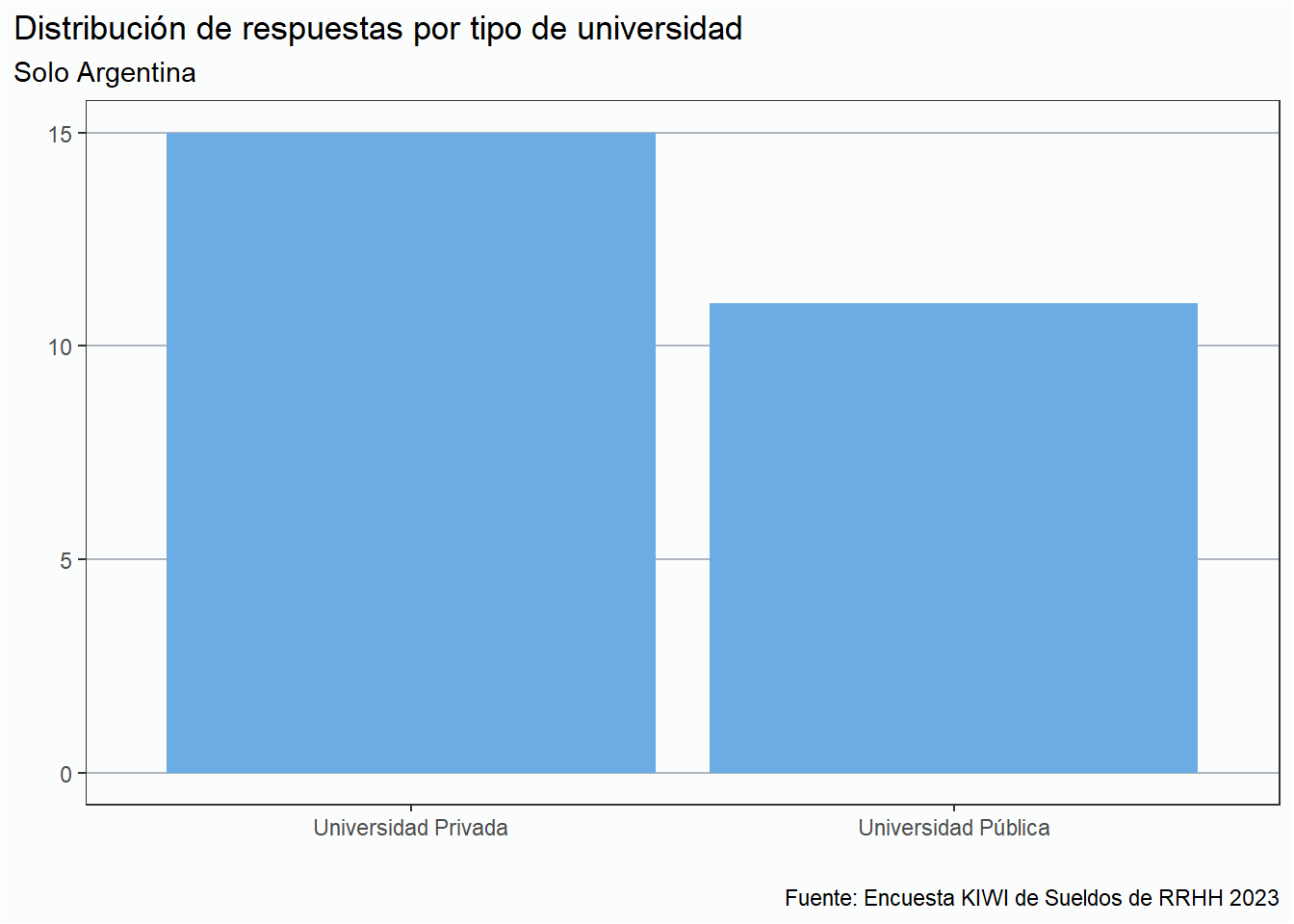
Limitandonos al país con mayor cantidad de respuestas, Argentina, en los siguientes graficos podemos observar que la distribución por tipo de Universidad es muy pareja , quedando un valor minimo y poco representativo para quienen no fueron a la Universidad:
Nos interesaba indagar cuál era el nivel de formación de los encuestados.
En la siguiente tabla podemos ver que la mayoría tiene estudios Universitarios completos:
Nivel de Formación
Cuenta
Universitario completo
12
Diplomado de posgrado completo
6
Universitario abandonado
4
Maestría o superior en curso
2
Terciario completo
2
Diplomado de posgrado en curso
1
Maestría o superior completa
1
Universitario en curso
1
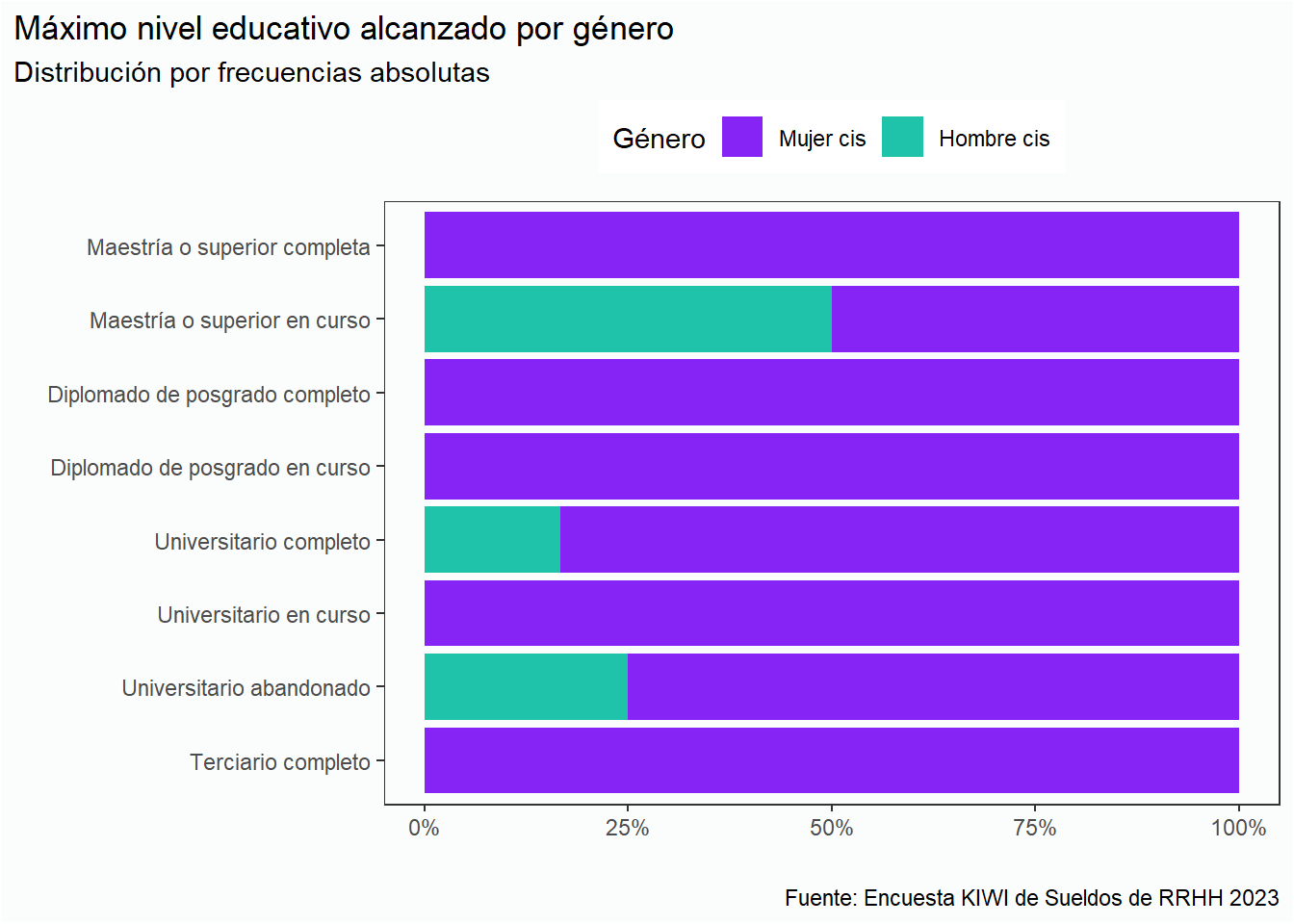
Cuando analizamos educación, nos resultó interesante analizar la distribución por género y nivel educativo.
En el siguiente gráfico podemos observar que las mujeres tienen mayor nivel de formación que los hombres:
Veamos los mismos resultados, en terminos relativos:
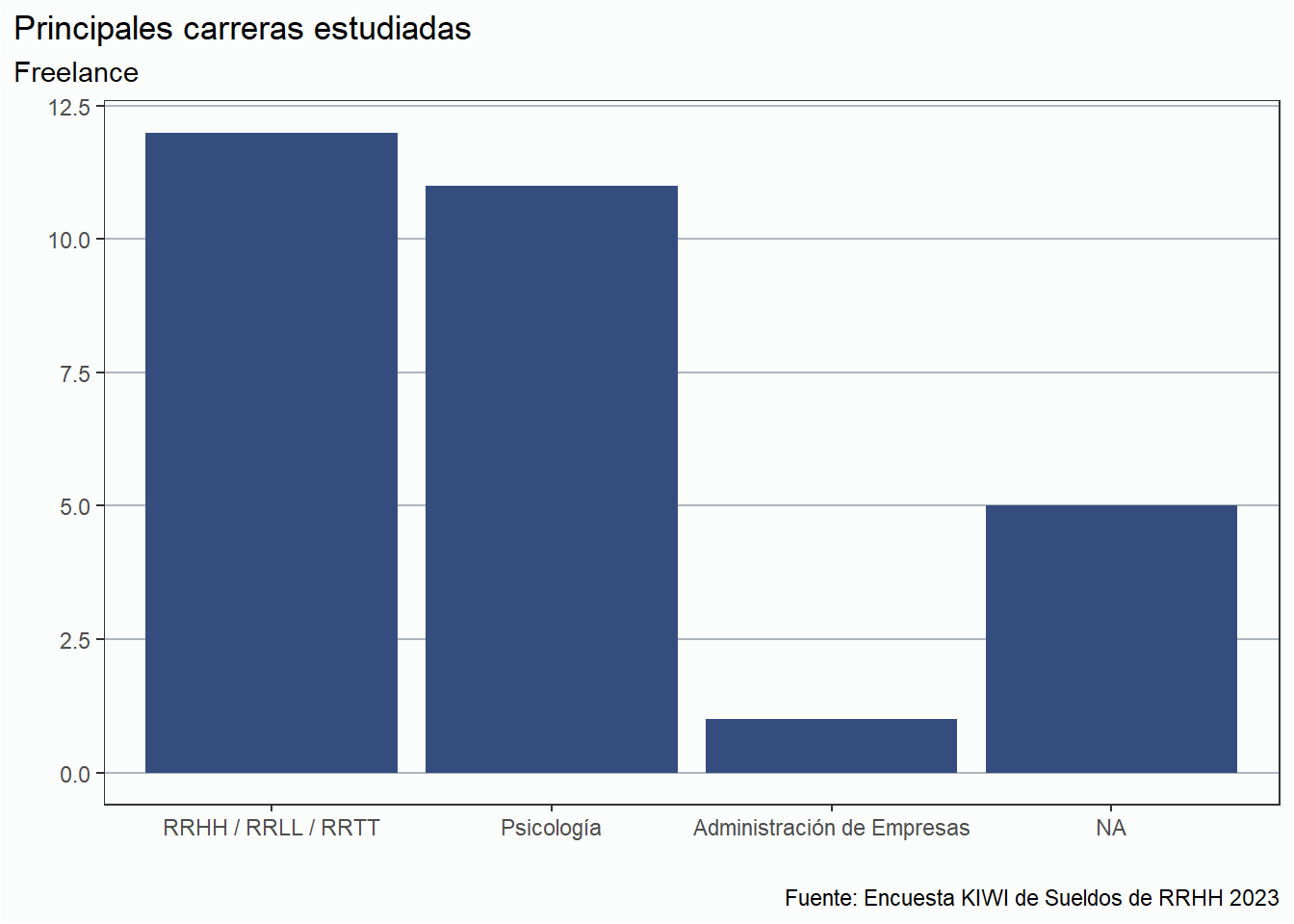
Respecto a las carreras, vemos que la tendencia de las mismas se corresponden con los resultados obtenidos en las personas en relación de dependencia:
Respuestas por Condición fiscal
La condidición fiscal de los encuestados la podemos observar en la siguiente tabla:
Registro Fiscal
Cuenta
Monotributista
20
Responsable inscripto
4
Contractor
3
Mi empresa esta registrada afuera de Arg
1
No tengo actividad fiscal en este momento
1
Respuestas por Exportación de Servicio
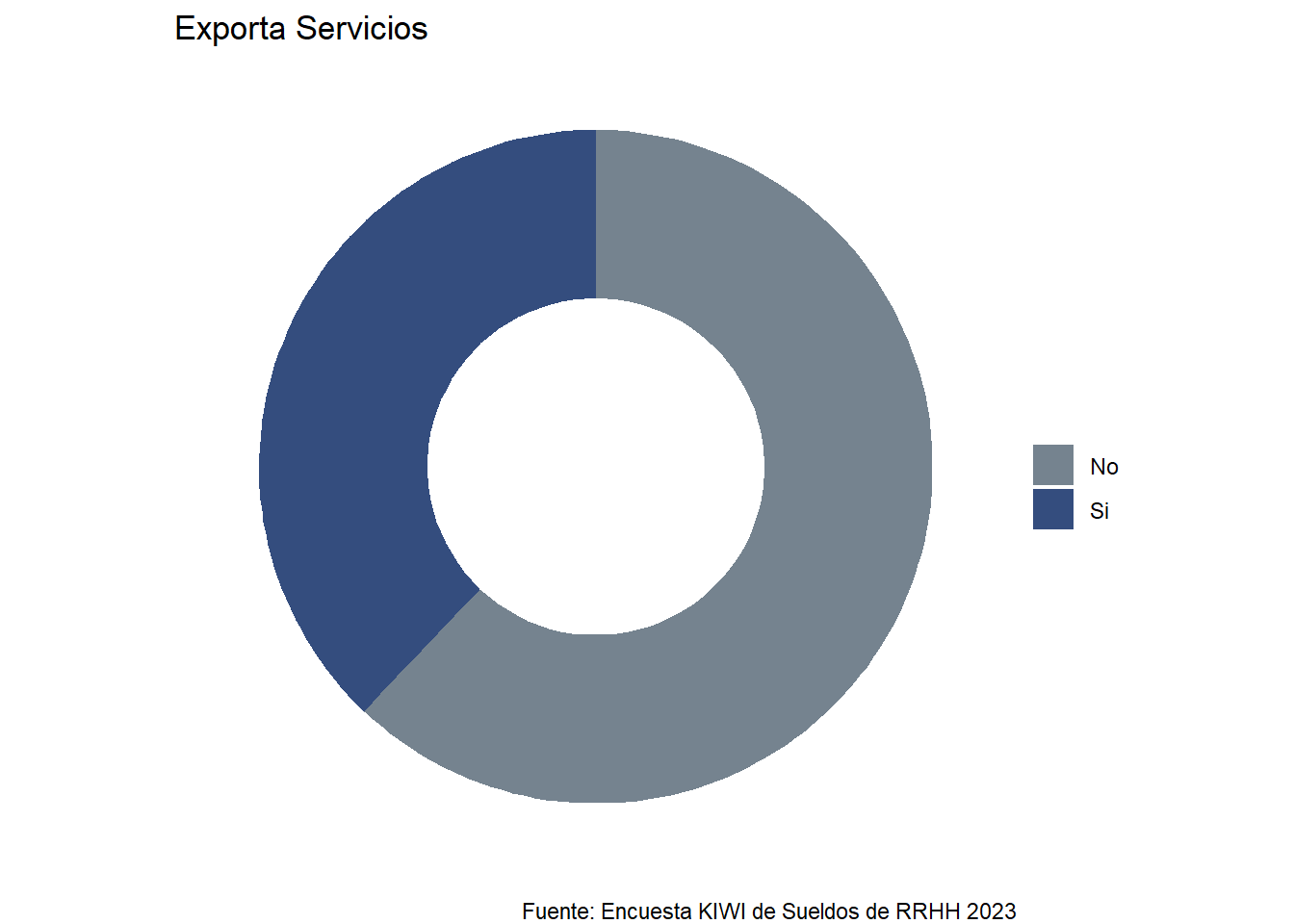
Como vemos a continuación, la mayoría no exporta sus servicios:
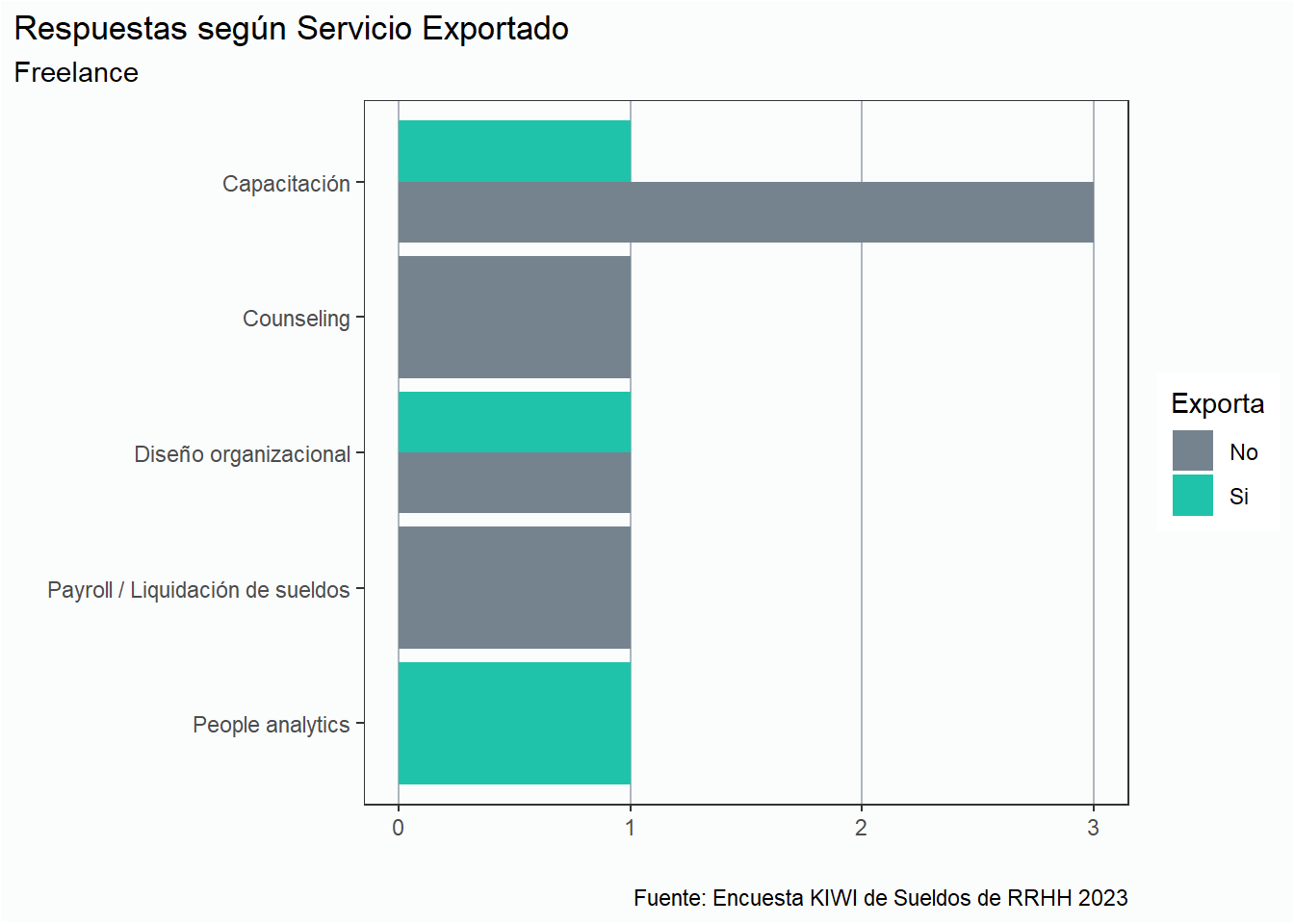
Focalizandonos entre quienes exportan, podemos ver cuál es el servicio prestado:
En relación a los medios de pago utilizados por quienes exportan, sus respuestas fueron las siguientes:
Medios de Pago Exterior
Cuenta
Payoneer
5
Cuenta en el exterior
3
Wise
2
Bitwage y lo vinculo con mis wallets de Crypto
1
Xxx
1
Respuestas por Antigüedad
Respecto a los años de experiencia como freelance, podemos observar que la mayoría tiene menos de dos años.
Un interrogante que nos surge en si la inserción en esta modalidad fue una decisión de carrera voluntaria o impulsada por las consecuencias de la pandemia. Carecemos de elementos para responder esa pregunta, por eso nos limitamos a presentar las respuestas obtenidas:
Años de Experiencia
Cuenta
Menos de 2 años
8
Entre 2 y 5 años
15
Entre 5 y 10 años
5
Más de 10 años
1
Respuestas por Búsquedas
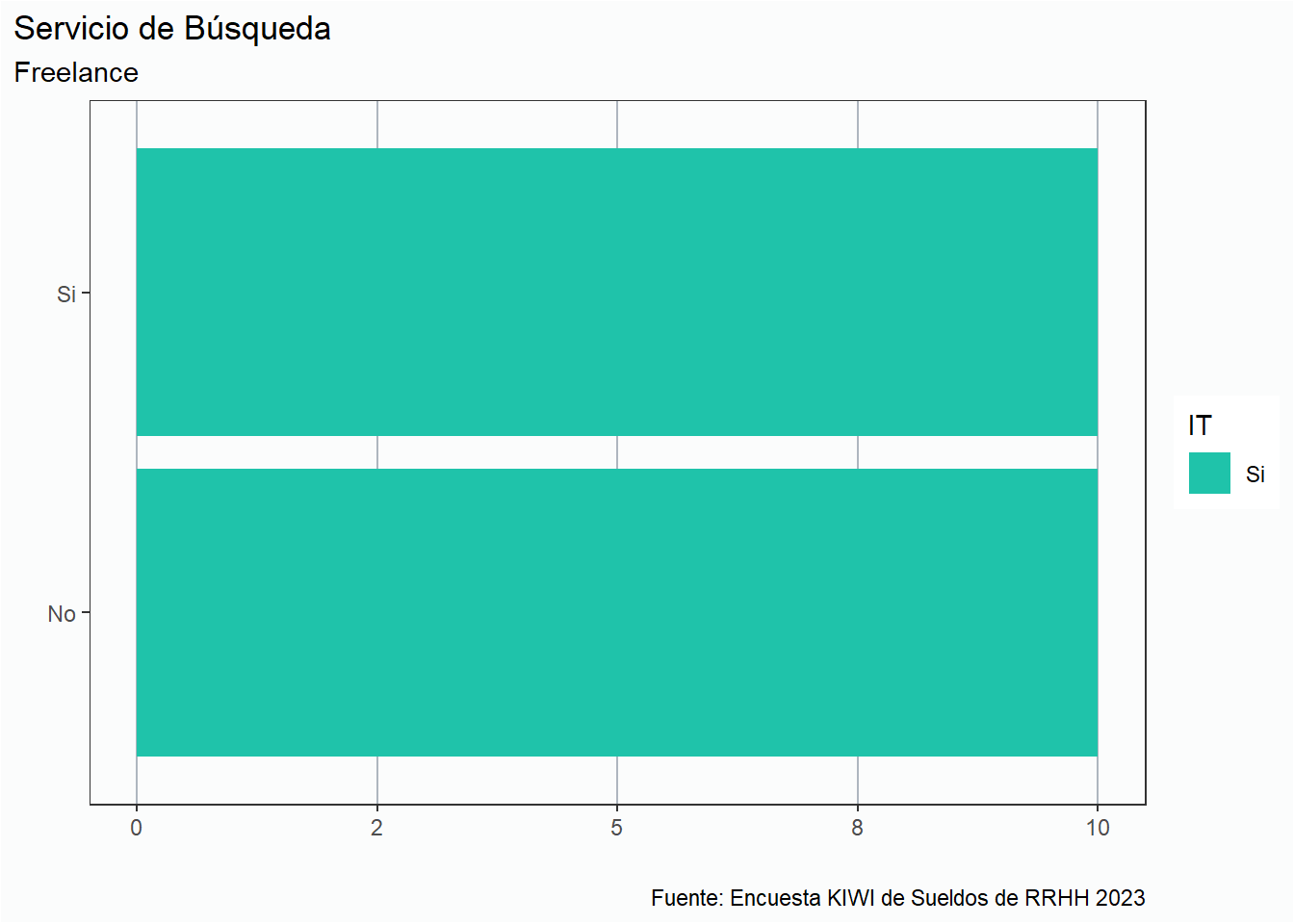
Nos interesa saber cuantos se dedican a realizar trabajos de selección de talentos.
Podemos observar que un 66% de las personas encuestadas en esta categoria se dedican a la tarea de búsqueda.
Serv. Búsqueda
n
freq
Si
20
69%
No
9
31%
Sabiendo el crecimiento y auge de las búsquedas en el sector de IT, veamos cuál es la participación de las mismas entre las personas que hacen recruiting.
Como se observa en el siguiente gráfico, la mayoría de las búsquedas se concentran que en el sector IT.
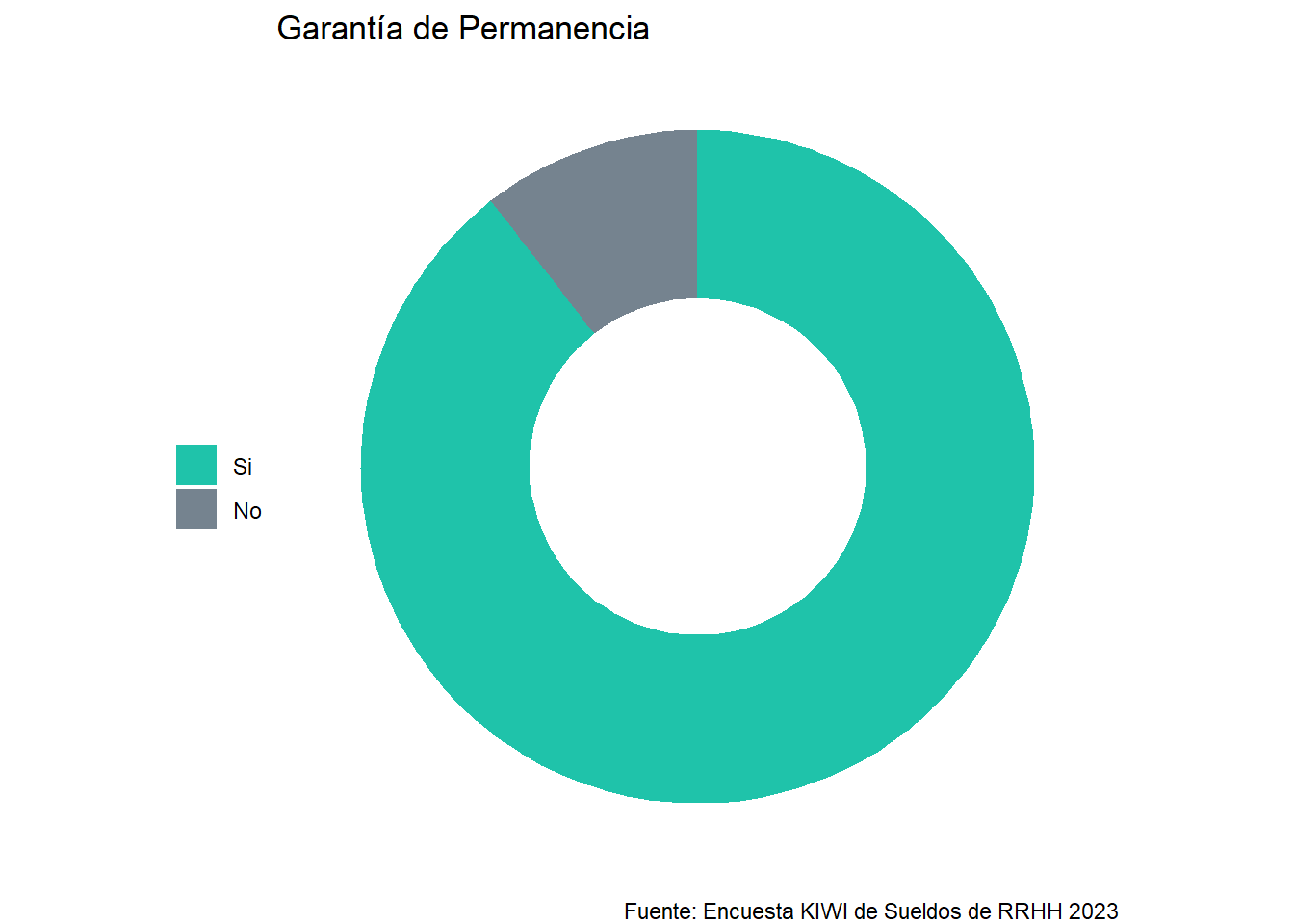
Respuesta por garantía de trabajo
Las garantías de reposición de vacantes se refieren a la protección que se brinda a cada cliente en el caso de que la persona contratada se marche de la empresa.
Veamos entre los que prestan el servicio de recruiting, quienes ofrecen garantía de permanencia del candidato.
En la siguiente tabla podemos observar que los plazos de garantía suelen ir desde un mes hasta los tres meses. Pero un número importante, no ofrece garantia por el servicio contratado.
Respuestas por Base de Coeficiente
Otro punto para destacar es el precio del servicio de quienes hacen recruiting.
Podemos ver que la gran mayoría cobra por dicho servicio, un porcentaje de remuneración mensual del ingresante, dejando para muy pocos casos el ingreso anual del mismo.
Una pregunta abierta que nos queda, es cuáles son las posiciones mejores pagas para los recruiters. Sin embargo, dicho análisis escapa de los objetivos de la presente encuesta.
Remuneración del Ingresante
Cuenta
Mensual
20
La mayoría cobra un porcentaje que va del 20% al 30% de las remuneraciones mensuales de los ingresantes, como podemos ver en el siguiente cuadro:
Porcentaje
Cuenta
20%
1
30%
1
40%
1
100%
2
Comunidades
R4HR es una comunidad abierta y gratuita. ¿Qué quiere decir esto? Que es es un espacio donde cualquier persona puede participar de la comunidad, sepa de R o no sepa nada, y además no hay que pagar nada por formar parte. También es un espacio seguro en el que cuidamos que haya acoso, insultos o abusos.
Las comunidades son una gran forma de construir conocimiento, de aprender, de generar relaciones, para resolver consultas, y también, por qué no, de hacer buenos amigos. Así que en esta sección nos proponemos ver cuáles son las comunidades más frecuentadas por las personas que participaron de la Encuesta.
Ver código
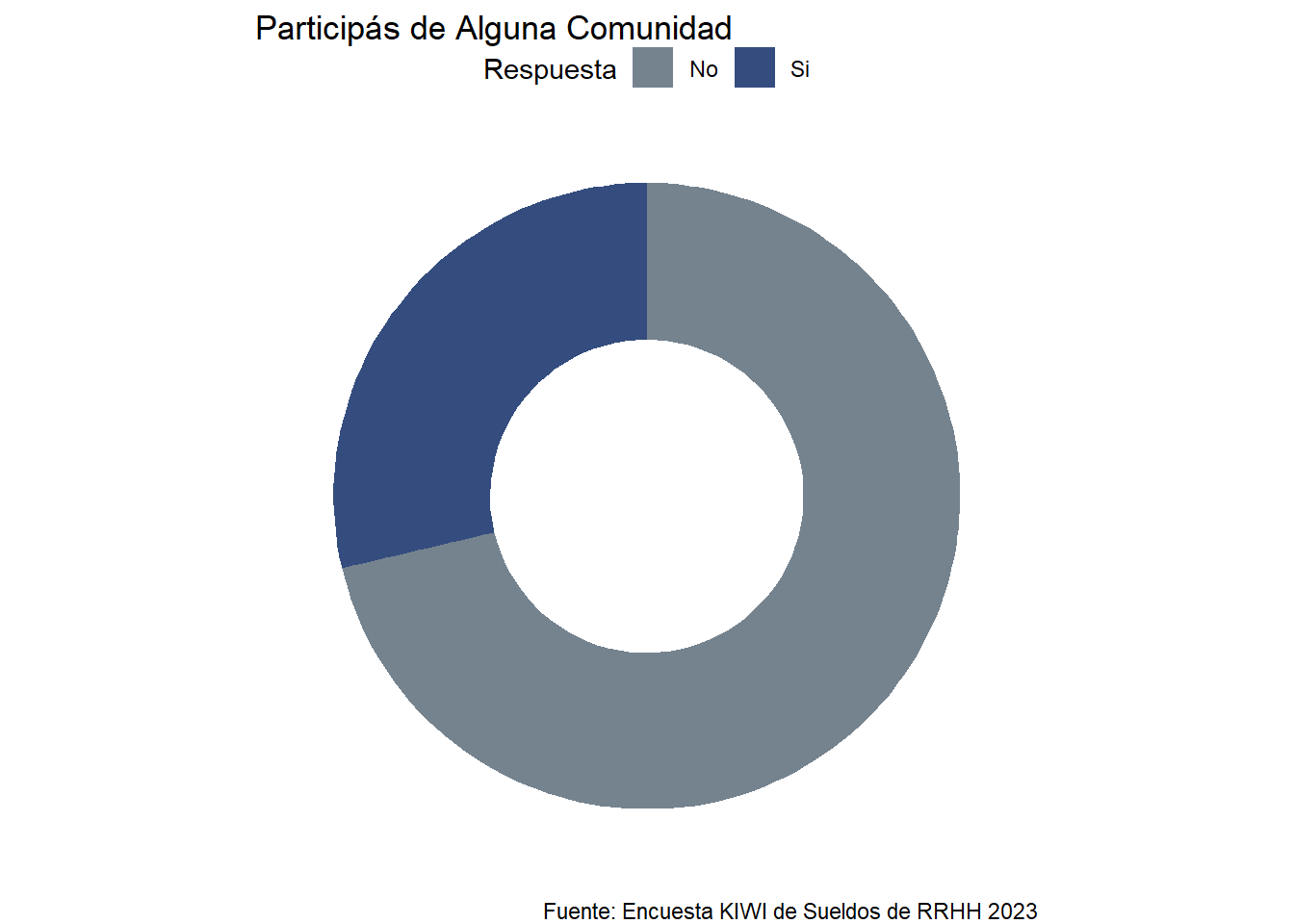
comunidad <- rh23 %>%select(pais, provincia, comunidad, comunidades)div <- comunidad %>%select(comunidad) %>%filter(!is.na(comunidad)) %>%group_by(comunidad) %>%summarise (n =n()) %>%mutate(freq = n/sum(n)) %>%arrange(-n)# Compute the cumulative percentages (top of each rectangle)div$ymax <-cumsum(div$freq)# Compute the bottom of each rectanglediv$ymin <-c(0, head(div$ymax, n=-1))# Compute label positiondiv$labelPosition <- (div$ymax + div$ymin) /2# Compute a good labeldiv$label <-paste0(div$comunidad, "\n Cant: ", div$n)# Make the plotggplot(div, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=comunidad)) +geom_rect() +coord_polar(theta="y") +# Try to remove that to understand how the chart is built initiallyxlim(c(2, 4)) +# Try to remove that to see how to make a pie chartscale_fill_manual(values =c(gris, azul)) +theme_void() +theme(legend.position ="top",panel.background =element_blank(),plot.title.position ="plot",text =element_text(family ="Roboto")) +labs(title ="Participás de Alguna Comunidad",fill ="Respuesta", caption = fuente)
Del total de respuestas, 29% (68) participan de alguna comunidad. Estas son las comunidades mencionadas.
En la tabla a continuación ponemos todas las comunidades que nos nombraron. No ponemos la cantidad de respuestas que obtuvo cada una porque no es una competencia.
Tené en cuenta lo siguiente: Para crear una comunidad sólo hace falta tener ganas de hacerlo. Lo mejor de las comunidades es que hay mucha gente dispuesta a compartir.
Ver código
comunidad <- comunidad %>%filter(!is.na(comunidades), comunidad =="Si") %>%select(pais, comunidades)comunidad <- comunidad %>%mutate(comunidades =str_replace(comunidades, "whats app|Whatsapp|Wsapp|wsp|whatsapp|grupos de whats app|Grupo de WhatsApp|W.App|grupos wsapp", "WhatsApp"),comunidades =str_replace(comunidades, "Adrha|Adhra|ADHRA|ADRHRA", "ADRHA"),comunidades =str_replace(comunidades, "Sclak de reclutamiento Latam", "Recruitment Latam"),comunidades =str_replace(comunidades, "Data 4 hr|Data4hr|DATA4HR", "Data 4HR"),comunidades =str_replace(comunidades, "Bench.Club|Benchclub|Bench", "Bench Club"),comunidades =str_replace(comunidades, "Aprhnoa", "APRHNOA"),comunidades =str_replace(comunidades, "Bench ClubClub", "Bench Club"),comunidades =str_replace(comunidades, "Aparh", "APARH"),comunidades =str_replace(comunidades, "slack tech recruiters arg|tech.recruiters.arg|Tech Recruiter|Recruitment Latam - en Slack", "Tech Recruiters Arg"),comunidades =str_replace(comunidades, "LinkdIn|Linkedin", "LinkedIn"),comunidades =str_replace(comunidades, "Uba", "UBA"),comunidades =str_replace(comunidades, "Interempresa Cordoba|Recursos Humanos Inter Empresas CBA", "RRHH Interempresas"),comunidades =str_replace(comunidades, "grupo", "Grupo"),comunidades =str_replace(comunidades, "Capital humano Talento femenino", "Capital Humano Talento Femenino"),comunidades =str_replace(comunidades, "Tendencia de Recursos Humanos Bolivia", "Tendencias en Recursos Humanos Bolivia"),comunidades =str_replace(comunidades, "PAS", "People Analytics Spain"),comunidades =str_replace(comunidades, "Grupos de Whatsapp", "Grupos de WhatsApp"),comunidades =str_replace(comunidades, "Grupos Whatsapp", "Grupos de WhatsApp")) # # Reemplazo manual de comunidades# comunidad[2,2] <- "Grupos de WhatsApp, ADRHA"# comunidad[6,2] <- "Bench Club, ADRHA"# comunidad[7,2] <- "Grupos de WhatsApp"# comunidad[9,2] <- "Grupos en LinkedIn, Grupos de WhatsApp"# comunidad[12,2] <- "Grupos de WhatsApp"# comunidad[13,2] <- "Grupo de WhatsApp Córdoba"# comunidad[14,2] <- "Club de R para RH, Grupo de WhatsApp Córdoba"# comunidad[17,2] <- "Club de R para RH"# comunidad[21,2] <- "Grupos de WhatsApp, Grupo Local, LinkedIn"# comunidad[22,2] <- "Grupos de LinkedIn"# comunidad[25,2] <- "Grupos de WhatsApp, LinkedIn"# comunidad[28,2] <- "Instagram, Grupos de WhatsApp"# comunidad[29,2] <- "ADRHA, Comunidad HR"# comunidad[42,2] <- "ADRHA, LinkedIn"# comunidad[48,2] <- "Tendencias en Recursos Humanos Bolivia, ASOBOGH"# comunidad[53,2] <- "Comunidad HR, Grupos de diferentes Universidades"# comunidad[59,2] <- "Grupos de Whatsapp, LinkedIn"# comunidad[64,2] <- "Red de RRHH, Grupo de WhatsApp Mar del Plata"# comunidad[69,2] <- "Grupo de Colegas RRHH (Consultora MJG) Buenos Aires y Latinoamerica"# comunidad[70,2] <- "ADRHA, Grupos Regionales"# comunidad[73,2] <- "Club de R para RH, Data 4HR, RRHH Interempresas, Reclutadores CBA"# comunidad[80,2] <- "Compensaciones, Bench Club"# comunidad[83,2] <- "Total Rewards Compensaciones"# Separamos las comunidades en columnas y luego pivoteamos para agruparlascomunidad %>%separate(col = comunidades, into =c("c1", "c2", "c3", "c4"), sep =",", fill ="right", remove =TRUE) %>%mutate(across(c("c1", "c2", "c3", "c4"), str_trim)) %>%pivot_longer(cols =c(c1:c4),names_to ="columna",values_to ="comunidad") %>%filter(!is.na(comunidad)) %>%filter(comunidad !="etc") %>%group_by(pais, comunidad) %>%tally() %>%ungroup() %>%select(-n) %>%rename("País"= pais,"Comunidad"= comunidad) %>%kable("html", escape=F) %>%kable_styling(full_width =TRUE, bootstrap_options =c("striped","hover","condensed" )) %>%row_spec(0, bold=T, color="white", background = azul)
País
Comunidad
Argentina
-
Argentina
ADRHA
Argentina
ADRHA/CAC/FAETT
Argentina
Asesorías eventuales en empleabilidad cuando se requiere
Argentina
Asoc RH de Misiones
Argentina
Asociación Misionera de RR.HH.
Argentina
Bench Club
Argentina
Busqueda y selección
Argentina
Clases en Universidad
Argentina
Comunidad Bench Club+ (organizado originalmente por Carolina Borrachia
Argentina
Consultoras
Argentina
Conversatorios de rrhh para rrhh
Argentina
Conversatorios y protocomunidades de RRHH en la ciudad
Argentina
Coworking
Argentina
De relaciones del trabajo
Argentina
Docente en la UBA
Argentina
Empujar
Argentina
Granito de arena
Argentina
Grupo RT
Argentina
Grupo compensaciones
Argentina
Grupo de WhatsApp BENCH+
Argentina
Grupo textil
Argentina
Grupos de RRHH de mi provincia; ONGs
Argentina
Grupos de colegas de Compensaciones y de HR en Mendoza
Argentina
HR Makers
Argentina
HRAnalytics ThinkTank
Argentina
IDEA
Argentina
Junior Achievement
Argentina
Miembro activo de asociacion de HR de la provincia
Argentina
Mujeres de RRHH
Argentina
OIT
Argentina
People Analytics Spain
Argentina
Privadas de profesionales de rrhh
Argentina
R4HR
Argentina
Recruitment Latam
Argentina
Rrhh interempresas
Argentina
SalesEra
Argentina
Sin Jr No Hay Sr
Argentina
Soy coordinadora del área de empleabilidad de una Fundación
Argentina
Tech Recruiters Arg
Argentina
Trabajo e Inclusion - UBA
Argentina
WhatsApp
Argentina
WhatsApp + ADRHA
Argentina
allí intercambiamos info y nos ayudamos desinteresadamente en cuestiones relacionadas a la profesión).